


11月 1, 2024
强化学习入门-Q学习
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过与环境的交互来学习如何采取行动,以最大化累积的奖励。以下是对强化学习原理...
1284 0

9月 2, 2024
MinHash-文本相似性计算
MinHash(最小哈希)是一种用于估算集合相似性的算法,它常用于处理大规模数据集的去重问题,尤其是当数据集非常大,无法一次性加载到内存中时。MinHash 主...
1148 0

8月 30, 2024
论文笔记——Llama 2: Open Foundation and Fine-Tuned Chat Models
Introduction 开源版本: Llama2 7B 13B 70B Llama 2-Chat 7B 13B 70B 训练过程: 1、通过公开数据集训练Ll...
1000 0

5月 29, 2023
论文笔记——[SIGGRAPH2023]Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Mani...
创新点: ①交互式的控制图片的变化 给定一对(handle point, target point),本方法以一种优化的方式执行图像操作。如上图所示,每个优化步...
1047 0


11月 8, 2022
论文笔记——[人脸3d重建][CVPR 2021 Oral]Inverting Generative Adversarial Renderer for Face Reconstruction
基础知识:基于3DMM的三维人脸重建技术总结 (潜码和噪声的概念见StyleGAN) (GAN逆转的文章见In-Domain GAN Inversion for...
1111 0

11月 6, 2022
论文笔记——[CVPR workshop 2022]Transformer for Single Image Super-Resolution
创新点: ①由轻量CNN主干Lightweight CNN Backbone(LCB)和轻量Transformer主干Lightweight Transform...
1554 0

11月 5, 2022
论文笔记——[CVPR 2022 Oral]Restormer: Efficient Transformer for High-Resolution Image Restoration
创新点: ①解决高分辨率图像的图像恢复任务中transformer复杂度高的问题 ②在图像运动去模糊,去焦去模糊,图像去噪(高斯灰度/颜色去噪,和真实图像去噪)...
1588 0

8月 10, 2022
论文笔记——HIPA: Hierarchical Patch Transformer for Single Image Super Resolution
创新点: ①对LR图像处理成分层次的子块,通过迭代的网络,形成从小到大不同size的区域。 ②基于通道注意力的位置编码策略。 ③基于卷积的多层注意力组 总体结构...
1236 0

7月 25, 2022
论文笔记——[ICCV 2021]Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks
创新点: ①从固定尺度中学习任意尺度的超分,且能处理不匀称尺度(高宽不成比例)。 ②通过对现有超分网络加入插件模块实现任意尺度的超分,该模块由多尺度感知的特征自...
1201 0
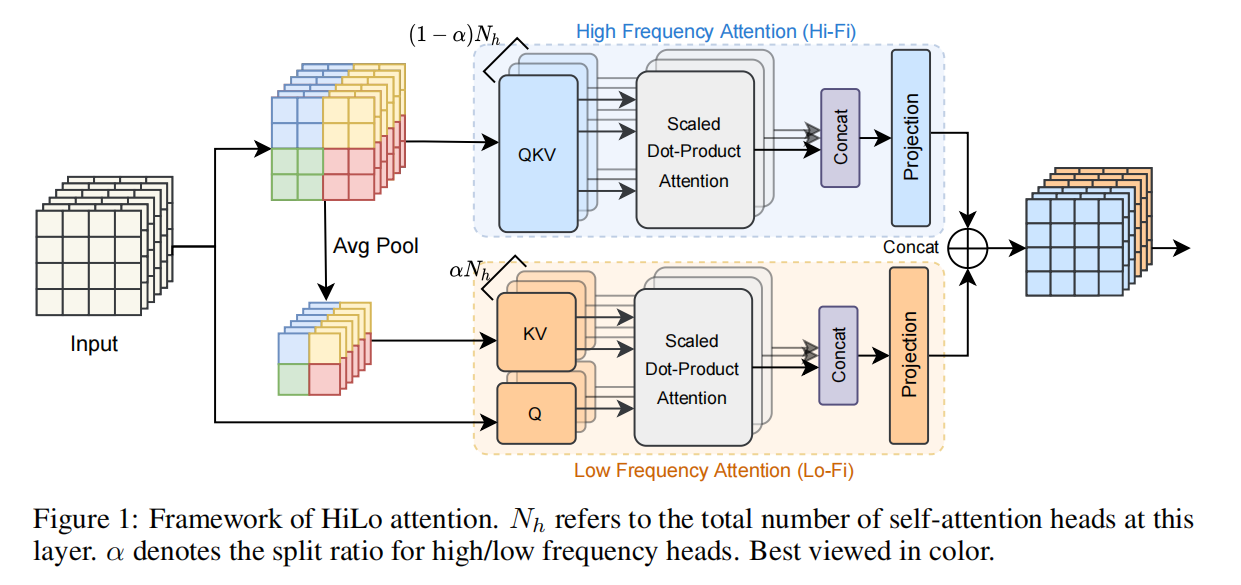
7月 21, 2022
论文笔记——Fast Vision Transformers with HiLo Attention
创新点: ①高频捕捉局部精细数据,低频聚焦全局结构 ②为了区分不同频率的独特性质,让attention中的不同头分为两组,分别进入进入高\低频注意力模块,高频通...
1792 1

7月 20, 2022
论文笔记——[AAAI 2022]Less is More: Pay Less Attention in Vision Transformers
创新点: ①在浅层用MLP编码局部特征 ②在深层用自注意力捕获长距离依赖 ③可变形的token融合模块,以非均匀的方式自适应地融合patch。 特点:减少计算成...
1160 3

7月 13, 2022
论文笔记——[ICCV 2021 Oral]Co-Scale Conv-Attentional Image Transformers
创新点: ①协同尺度的卷积注意力机制(并行、串行) ②通过卷积实现embedding的相对位置(减少计算量) 基于卷积的的注意力模块总体结构 分析自注意力机制 ...
1148 1

7月 13, 2022
论文笔记——[CVPR 2020]Learning Spatial Attention for Face Super-Resolution
创新点: ①空间注意力机制 ②加入鉴别器,可以让网络生成多尺度图像(SPARNetHD) 总体结构 主要由三个模块构成: 降尺度模块 特征提取模块 升尺度模块 ...
737 1

7月 3, 2022
论文笔记——[CVPR 2022]Vision Transformer with Deformable Attention
创新点: ①以数据依赖的方式在自注意力计算中选择K和V对。 ②通过一个网络学习offset坐标,采用双线性插值计算位置。 与其他网络的对比(Attention模...
1263 0
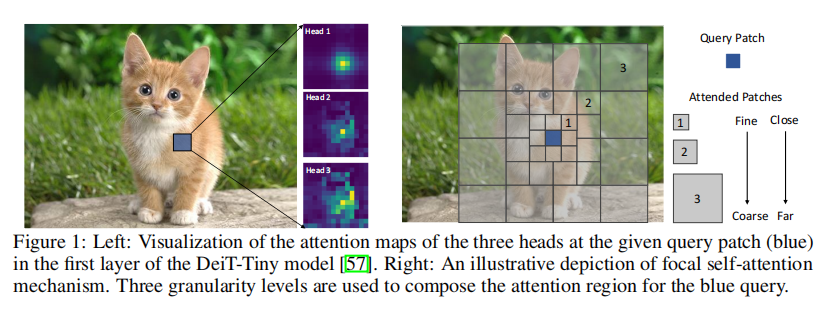
7月 1, 2022
论文笔记——[NeurIPS 2021]Focal Self-attention for Local-Global Interactions in Vision Transformers
创新点: ①通过距离来算自注意力,距离近的patch比较精细,距离远的比较粗糙,从而减少大分辨率图像的计算量 总体结构 总体结构与传统的Vit相差不大,每个pa...
698 0

7月 1, 2022
论文笔记——[CVPR 2022 Oral]MetaFormer is Actually What You Need for Vision
创新点: ①Transformer中的自注意力机制没用,结构才有用 ②即便把Attention模块换成Pooling,也能得到提升 总体结构 本文把Attent...
796 0

6月 30, 2022
论文笔记——[CVPR2022]A ConvNet for the 2020s
创新点: ①通过finetune让ResNet-50达到Transformer的准确率 以下文章已经描述得很清晰,就不再赘述了: https://zhuanla...
797 0
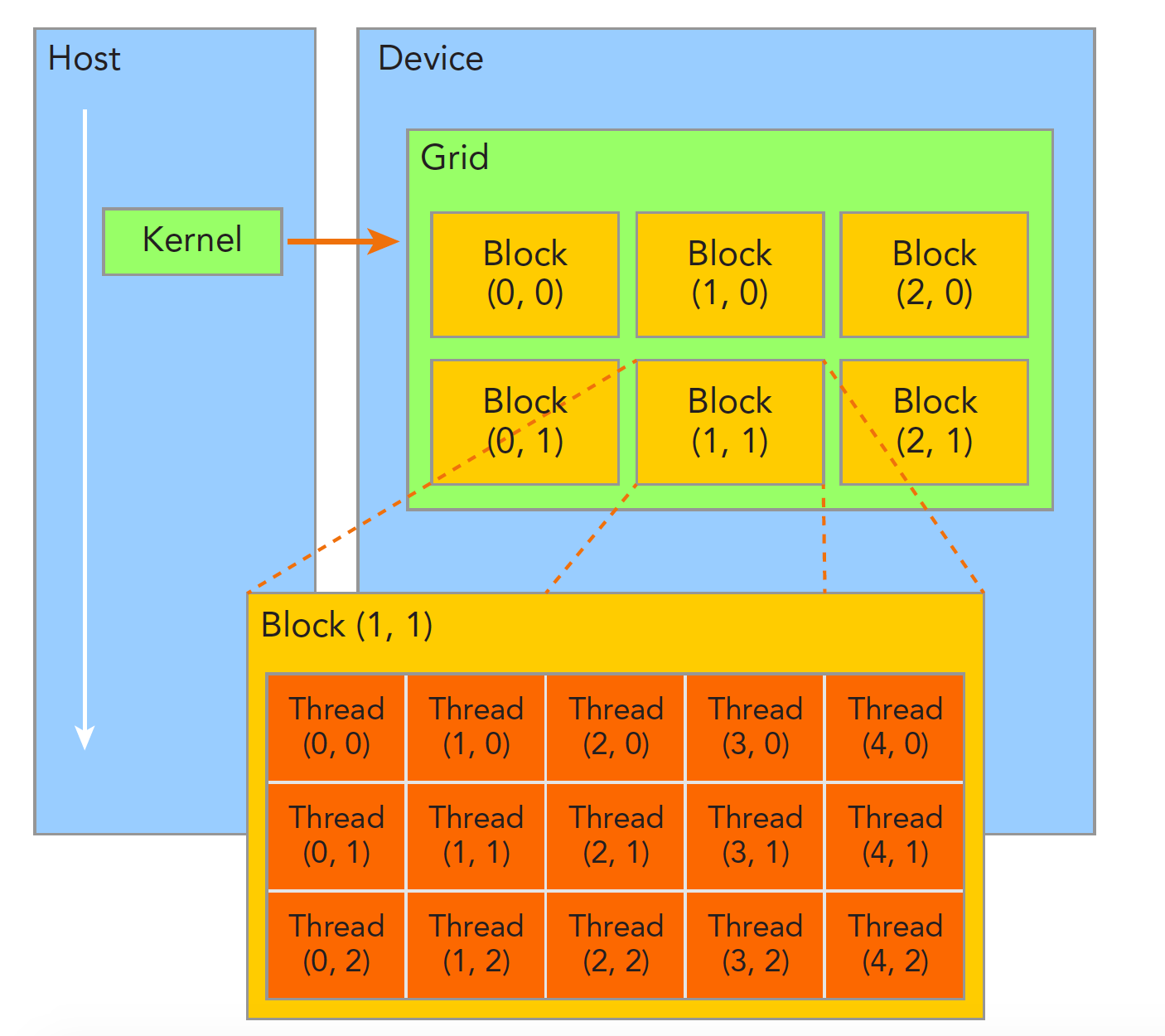
6月 30, 2022
MindSpore算子开发——CUDA代码优化
CUDA编程入门:谭升的博客 对于cuda编程,核心是如何高效率地利用多线程,每个线程完成一个小任务,最终实现完成一个算子任务。 一个核函数只能有一个grid,...
747 0

6月 8, 2022
论文笔记——[CVPR2022]StyleSwin: Transformer-based GAN for High-resolution Image Generation
创新点: ①双重关注,同时利用局部窗口和移动窗口的上下文 ②充分利用了窗口中的绝对位置知识(正弦位置编码) ③用小波鉴别器(wavelet discrimina...
980 0