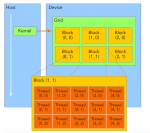
CPU和GPU的区别:CPU计算性能强,但是一次只能处理几件事情。GPU计算性能弱,但是能同时处理大量的计算。

(ALU: Arithmetic and Logic Unit)
局部性原理
时间局部性:程序最近访问的地址在不久的将来很可能再次被访问的特性。
cache就是一个充分利用时间局部性的典范。在每个GPU block中都存在当前block线程共享的cache内存,频繁访问的数据或者变量可以存在此处。
空间局部性:当程序访问某存储器地址后,很可能马上访问其邻近地址的特性。
根据这个特性,当输入tensor过大,一个线程需要完成多个工作时,可以优先让线程完成相邻空间的工作,而非传统的:
for (size_t pos = blockIdx.x * blockDim.x + threadIdx.x; pos < out_size; pos += blockDim.x * gridDim.x) {
...
}在算子ExtractVolumePatches中,按照输出的个数定线程数(线程数不够则一个线程处理多个位置),每个线程需要找到对应的输入位置的元素。注意到每个窗口中存在相邻的元素,如下图的红框部分
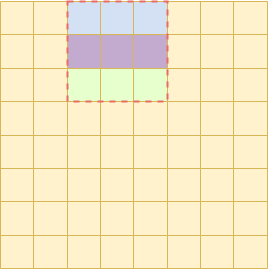
于是当线程数不足的时候,可以让一个线程做一个窗口中相邻空间的工作(如上图中蓝色,紫色,绿色)。而且每个线程的工作只是给输出位置赋值一次,不会因为争抢锁导致性能下降。减少了大量的位置计算。
循环展开(#pragma unroll)
执行核函数时,通常以warp为单位去执行指令的。当warp去执行循环时(线程ID去做for的判断条件,或者for里有线程ID的if条件),会产生分支冲突,增加指令数。
所以循环展开可以有效避免分支冲突,提高性能。
线程同步(__syncthreads();)
__syncthreads():block内的线程同步。
线程同步时需要注意,是否有分支会导致个别线程花费大量时间,尽量让所有线程都完成相同工作。
规约思想
规约加:当需要把多个数累加到一个位置时,由于线程之间资源抢占,导致线程花费了大量时间在等待资源上。于是可以用规约的思想,减少线程等待锁的时间,如下图所示。
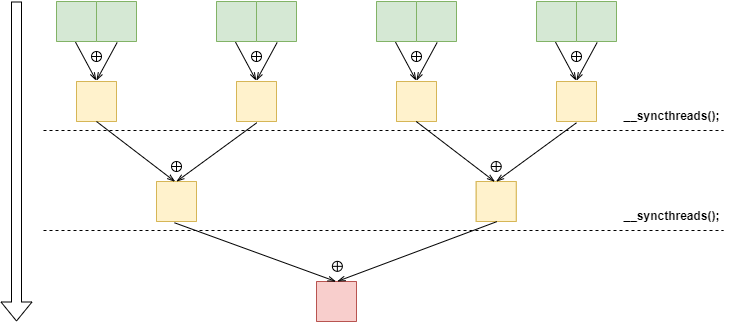
其中黄色方块申请的是block内的共享内存。
双调排序(Bitonic sorter)代码解析
双调排序是排序网络中最快的方法之一,属于多路归并的排序算法。当机器可以同时处理多个比较器时,排序的速度会大大提升。该算法由Ken Batcher设计,串行的时间复杂度为O(nlog^2n),同时也是比较次数。而并行时时间复杂度可以认为是O(log^2n)
首先我们需要知道什么是双调序列,双调序列是其中元素首先按递增顺序然后在某个特定索引之后开始递减的序列或这种序列的循环移位。如1, 2, 3, 4, 5, 3, 0。
思想:
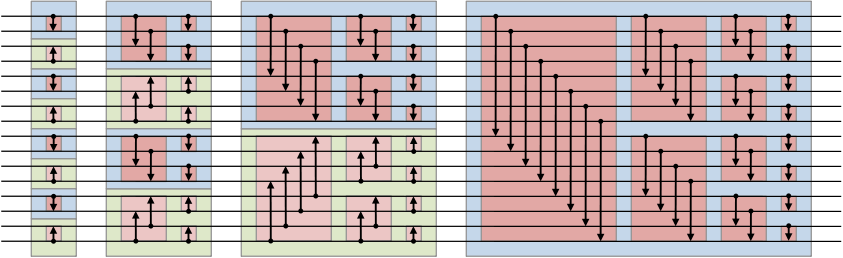
其中箭头是比较器,比较以确保箭头指向较大的数字。
替代表示
上图中,每个绿色框执行与蓝色框相同的操作,但排序方向相反。因此,每个绿色盒子都可以被一个蓝色盒子取代,于是双调序列变成单调序列,但是我们只要依然按照双调的原理来比较,便可以得到一种简便表示。
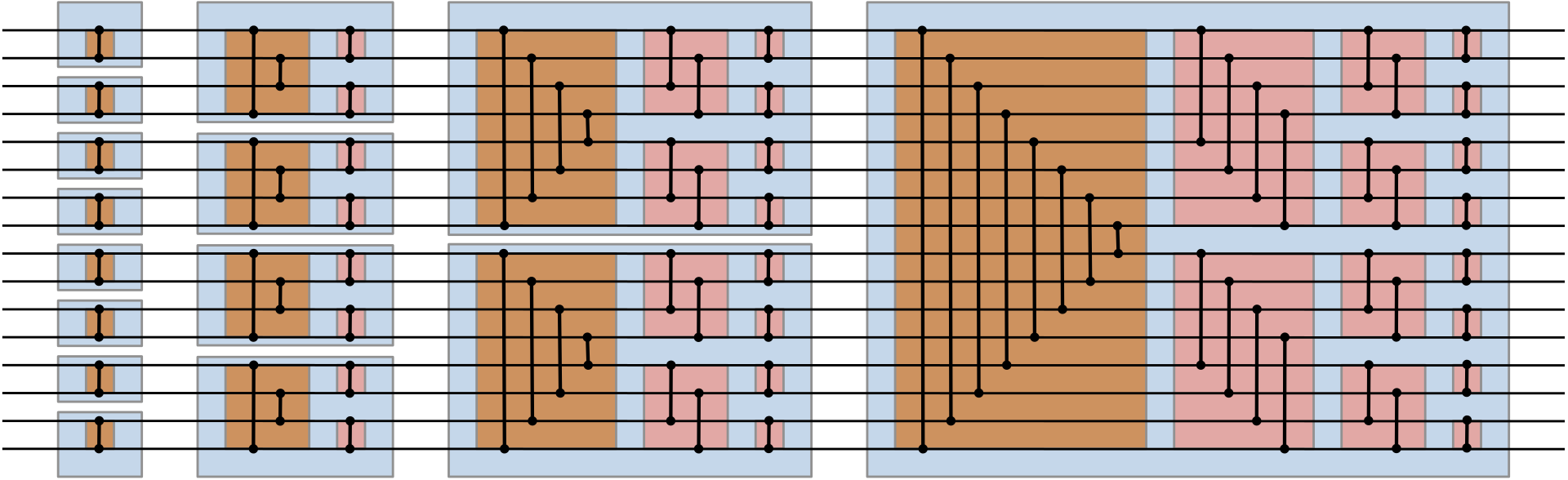
不需要绘制箭头,因为每个比较器都沿同一方向排序。蓝色和红色块执行与以前相同的操作。橙色块等效于红色块,其中其输入的下半部分和输出的下半部分的序列顺序相反。这是双调排序网络最常见的表示形式。
值得注意的是,双调排序要求输入个数必须是2的次方数,如果不满足,则可以给输入补充当前类型的最大值,直到输入个数等于2的次方数
计算大于当前v的最小2的次方数(类型为int):
int RoundUpPower2(int v) {
v--;
v |= v >> 1;
v |= v >> 2;
v |= v >> 4;
v |= v >> 8;
v |= v >> 16;
v++;
return v;
}双调排序CPU实现:
// given an array arr of length n, this code sorts it in place
// all indices run from 0 to n-1
for (k = 2; k <= n; k *= 2) // k is doubled every iteration
for (j = k/2; j > 0; j /= 2) // j is halved at every iteration, with truncation of fractional parts
for (i = 0; i < n; i++)
l = bitwiseXOR (i, j); // in C-like languages this is "i ^ j"
if (l > i)
if ( (bitwiseAND (i, k) == 0) AND (arr[i] > arr[l])
OR (bitwiseAND (i, k) != 0) AND (arr[i] < arr[l]) )
swap the elements arr[i] and arr[l]双调排序CUDA实现:
template <typename T>
__global__ void BitonicSort(const int ceil_power2, T *input) {
for (size_t i = 2; i <= ceil_power2; i <<= 1) {
for (size_t j = (i >> 1); j > 0; j >>= 1) {
for (size_t tid = threadIdx.x; tid < ceil_power2; tid += blockDim.x) {
size_t tid_comp = tid ^ j;
if (tid_comp > tid) {
if ((tid & i) == 0) {
if (input[tid] > input[tid_comp]) {
Swap(&input[tid], &input[tid_comp]);
}
} else {
if (input[tid] < input[tid_comp]) {
Swap(&input[tid], &input[tid_comp]);
}
}
}
}
__syncthreads();
}
}
}