CUDAзј–зЁӢе…Ҙй—Ёпјҡи°ӯеҚҮзҡ„еҚҡе®ў
еҜ№дәҺcudaзј–зЁӢпјҢж ёеҝғжҳҜеҰӮдҪ•й«ҳж•ҲзҺҮең°еҲ©з”ЁеӨҡзәҝзЁӢпјҢжҜҸдёӘзәҝзЁӢе®ҢжҲҗдёҖдёӘе°Ҹд»»еҠЎпјҢжңҖз»Ҳе®һзҺ°е®ҢжҲҗдёҖдёӘз®—еӯҗд»»еҠЎгҖӮ
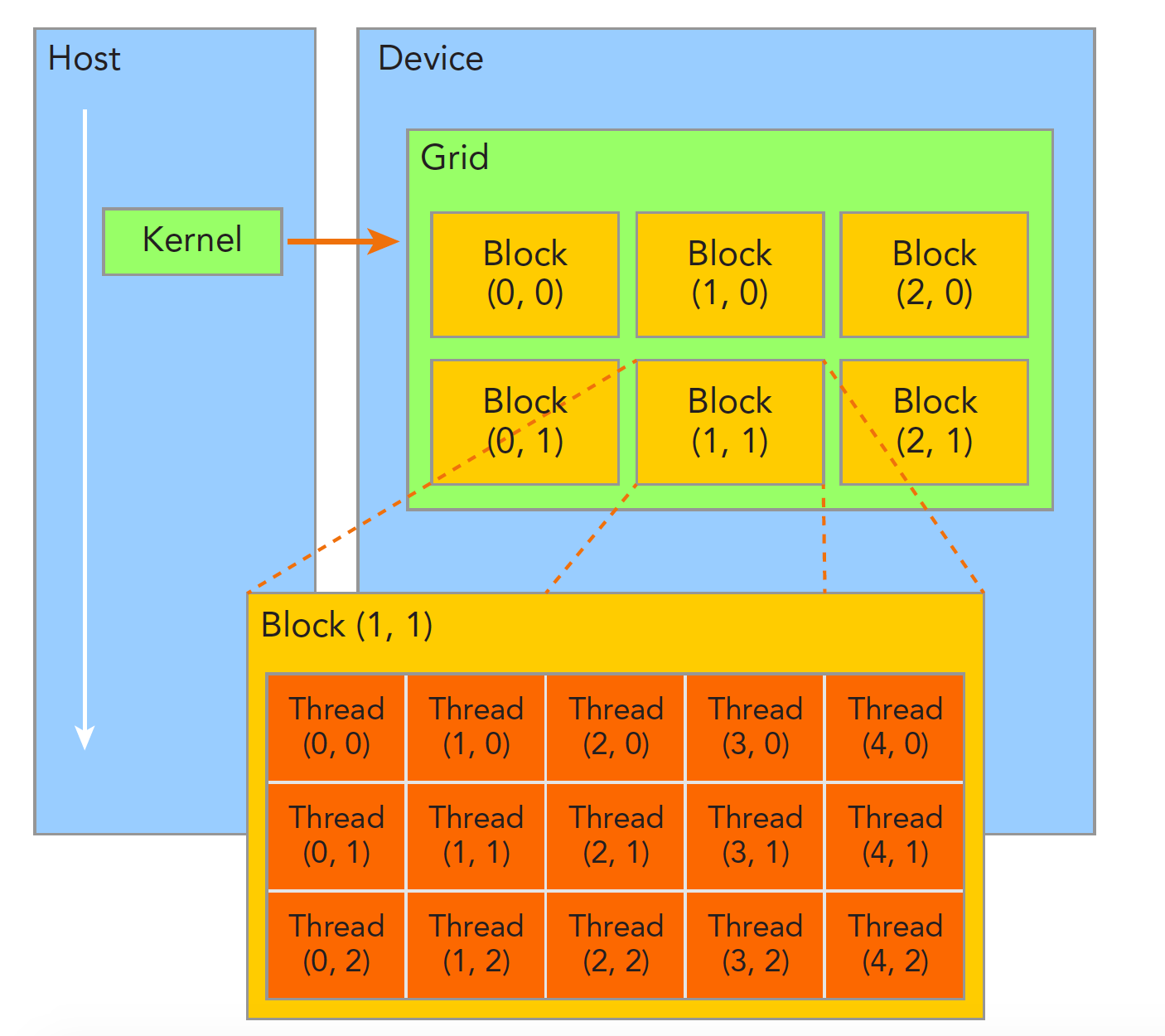
дёҖдёӘж ёеҮҪж•°еҸӘиғҪжңүдёҖдёӘgridпјҢдёҖдёӘgridеҸҜд»ҘжңүеҫҲеӨҡдёӘеқ—пјҢжҜҸдёӘеқ—еҸҜд»ҘжңүеҫҲеӨҡзҡ„зәҝзЁӢгҖӮ
жҜҸдёӘзәҝзЁӢйҖҡиҝҮзәҝзЁӢеҸ·е”ҜдёҖж ҮиҜҶпјҢзәҝзЁӢеҸ·ең°иҺ·еҫ—йҖҡиҝҮпјҡ
int64_t ourOutputPoint = threadIdx.x + blockIdx.x * blockDim.x;
int64_t plane = blockIdx.y;
int64_t batch = blockIdx.z;еӣ дёәдёҖдёӘgridйҮҢйқўзҡ„blockжҳҜдёүз»ҙзҡ„пјҢеҜ№дәҺNCHWзұ»еһӢзҡ„TensorпјҢйҖҡеёёpytorchдјҡжҠҠNз»ҙж”ҫеңЁblockIdx.zпјҢCз»ҙж”ҫеңЁblockIdx.yпјҢд»ҺиҖҢй«ҳж•Ҳең°еҲ©з”ЁзәҝзЁӢгҖӮ
еЈ°жҳҺgridе’Ңblockзҡ„ж—¶еҖҷпјҢжңүеҸҜиғҪеӣ дёәshapeеӨӘеӨ§еҜјиҮҙеЈ°жҳҺзҡ„зәҝзЁӢеқ—дёҚи¶іпјҢеҜјиҮҙжҠҘй”ҷпјҢдәҺжҳҜиҰҒи®ҫзҪ®дёҖдёӘжңҖеӨ§blockе’Ңthreadsж•°пјҡ(д»Јз ҒжқҘиҮӘpytorch)
dim3 grid(
(H*W + 127) / 128, // ceil(outputPlaneSize / 128)
C,
N);
dim3 block(H*W > 128 ? 128 : H*W);жңүеҸҜиғҪеӣ дёәе…ғзҙ еӨӘеӨҡпјҲдәҝдёҮзә§пјүпјҢеҜјиҮҙзәҝзЁӢж•°дёҚи¶ід»Ҙе®ҢжҲҗеҰӮжӯӨеӨҡд»»еҠЎпјҢдәҺжҳҜеҸҜд»Ҙи®©жҜҸдёӘзәҝзЁӢе®ҢжҲҗдёӨдёӘеҸҠд»ҘдёҠзҡ„д»»еҠЎпјҡпјҲд»Јз ҒжқҘиҮӘmindsporeпјү
template <>
__global__ void Fractionalmaxpool3dwithfixedksize) {
for (size_t pos = blockIdx.x * blockDim.x + threadIdx.x; pos < outer_size; pos += blockDim.x * gridDim.x) {
еҚ•дёӘзәҝзЁӢзҡ„д»»еҠЎ
}
return;
}еңЁи®Ўз®—жҹҗдәӣз®—еӯҗж—¶пјҢз”ұдәҺGPUзҡ„ең°еқҖз©әй—ҙдёҚдјҡеҲқе§ӢеҢ–дёә0пјҢжүҖд»ҘеҸҜиғҪйңҖиҰҒжүӢеҠЁеҲқе§ӢеҢ–пјҡпјҲд»Јз ҒжқҘиҮӘmindsporeпјү
template <typename T>
__global__ void InitOutput(T *output, const int64_t outer_size) {
T zero = 0;
for (size_t id = blockIdx.x * blockDim.x + threadIdx.x; id < outer_size; id += blockDim.x * gridDim.x) {
output[id] = zero;
}
return;
}еңЁеӨҡдёӘзәҝзЁӢдәүеӨәеҗҢдёҖдёӘең°еқҖж—¶пјҢе–„з”ЁеҺҹеӯҗеҠ гҖӮ

