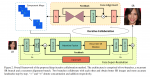
创新点:
①空间注意力机制
②加入鉴别器,可以让网络生成多尺度图像(SPARNetHD)
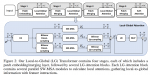
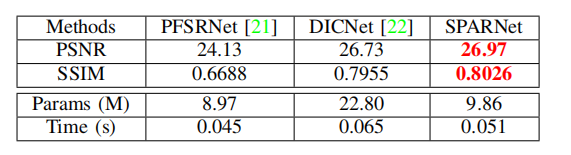
总体结构

主要由三个模块构成:
- 降尺度模块
- 特征提取模块
- 升尺度模块
低分图像首先经过双线性插值提升到与输出图像大小相当,然后进入SPARNet网络来产生高分图像。
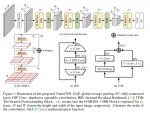
空间注意力机制(Face Attention Unit)
通过引入一个空间注意力分支,来单独学习空间注意力信息。
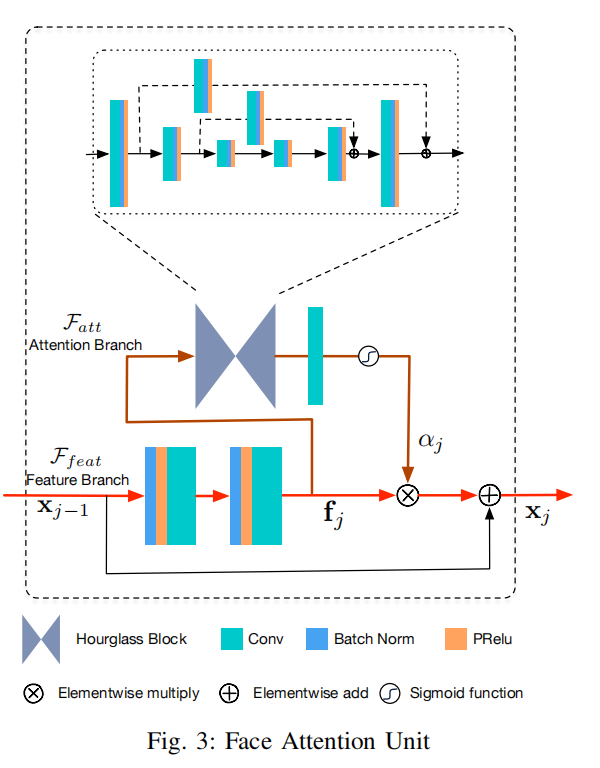
沙漏块(Hourglass Block)结构:
升降尺度模块
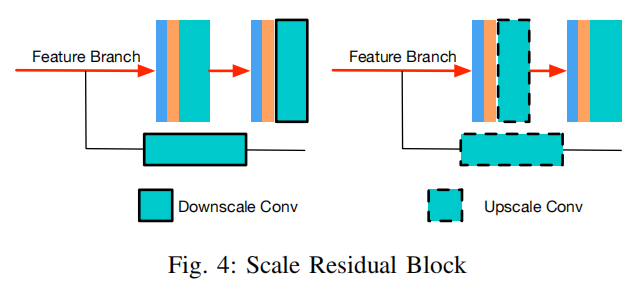
- 下采样采用普通卷积,步长为2
- 上采样采用最近邻上采样层
损失函数
- Pixel loss: 采用L1范数的逐像素损失。
- Adversarial loss:
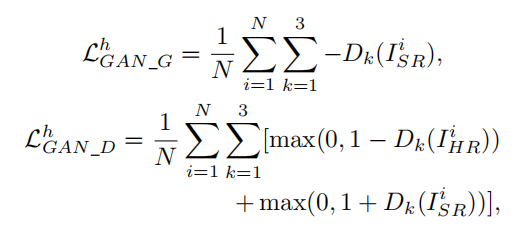
- Feature matching loss: 鉴别器的空间特征损失,用于稳定GAN的训练
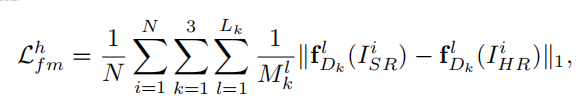
- Perceptual loss: 基于VGG19的感知损失,有助于约束人脸图像的高级语义
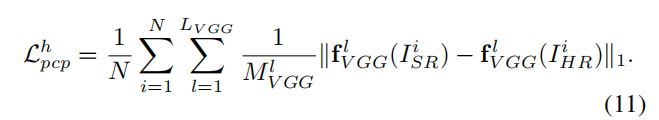
总损失
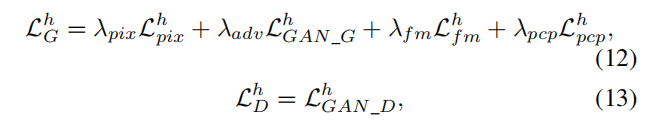
结果
![论文笔记——[CVPR2022]A ConvNet for the 2020s](https://blog.liguanxin.cn/wp-content/uploads/2022/06/微信截图_20220630121941-150x101.png)
![论文笔记——[人脸3d重建][CVPR 2021 Oral]Inverting Generative Adversarial Renderer for Face Reconstruction](https://blog.liguanxin.cn/wp-content/uploads/2022/11/微信截图_20221107142415-150x83.png)
![论文笔记——[SIGGRAPH2023]Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://blog.liguanxin.cn/wp-content/uploads/2023/05/微信截图_20230529202716-150x53.png)