创新点:
(1)非常深的残差通道注意网络(RCAN),用于高精度的图像SR。我们的RCAN可以比以前的基于cnn的方法更深入,并获得更好的SR性能。
(2)残差到残差(residual in residual)(RIR)结构来构建非常深的可训练网络。RIR中的长、短跳连接有助于绕过丰富的低频信息,使主网络学习到更有效的信息。
(3)通道注意(CA)机制,通过考虑特征通道之间的相互依赖关系来自适应地缩放特征。这种CA机制进一步提高了网络的表征能力。
关键点:残差群RG、长跳连接LSC、短跳连接SSC、通道注意力机制CA
由于用了非常多残差连接,网络深度甚至可以达到400层。
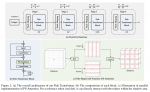
整体结构
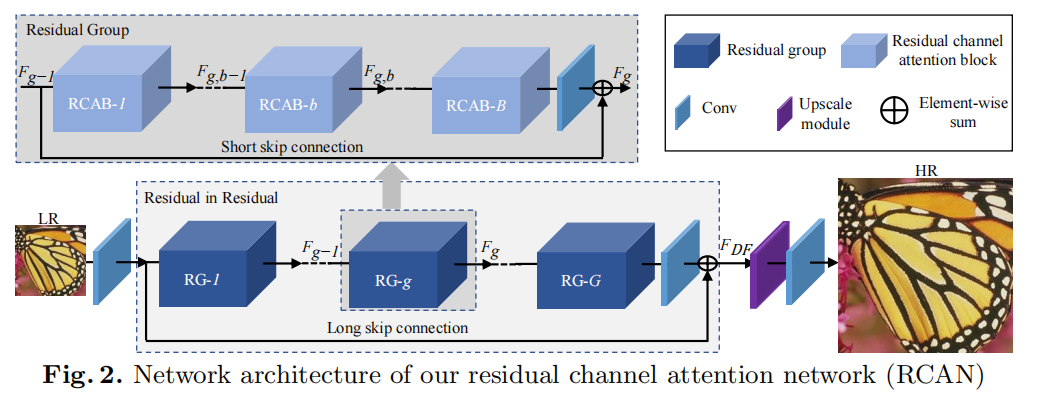
主要包括四个部分:浅层特征提取、残差(RIR)深度特征提取、上采用模块和重建部分。
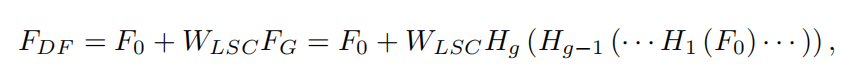
WLSC表示RIR最后一个卷积层后采用的权重。
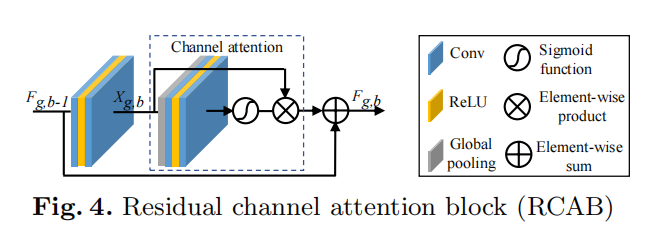
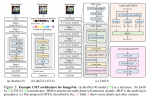
通道注意力机制CA
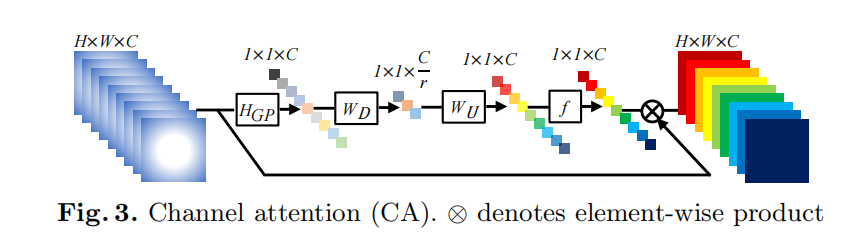
通道注意(CA)机制,通过建模特征通道之间的相互依赖关系,自适应地重新调整每个通道级特征。这样的CA机制允许我们提出的网络集中于更有用的网络。
主要步骤:利用全局平均池化方法将通道级的全局空间信息引入通道token。
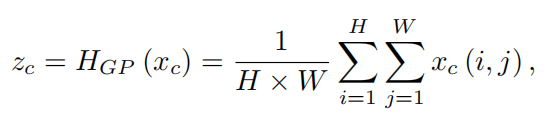
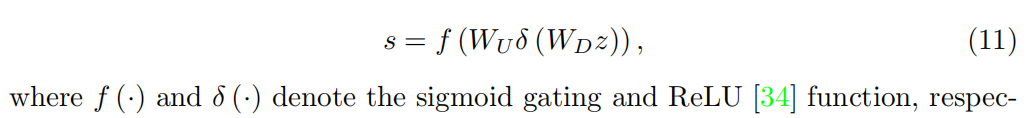
WD是卷积层的权重。
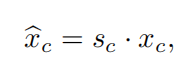
sc是缩放比例,xc是特征map。
RCAB: B个residual channel attention blocks
损失函数
L1范数
CODE
CA层,对应
## Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * yRCAB层,对应
## Residual Channel Attention Block (RCAB)
class RCAB(nn.Module):
def __init__(
self, conv, n_feat, kernel_size, reduction,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(RCAB, self).__init__()
modules_body = []
for i in range(2):
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias)) # 卷积
if bn: modules_body.append(nn.BatchNorm2d(n_feat))
if i == 0: modules_body.append(act) # 图4中的ReLU层
modules_body.append(CALayer(n_feat, reduction)) # 加入CA层
self.body = nn.Sequential(*modules_body)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x)
#res = self.body(x).mul(self.res_scale)
res += x
return resRG层,对应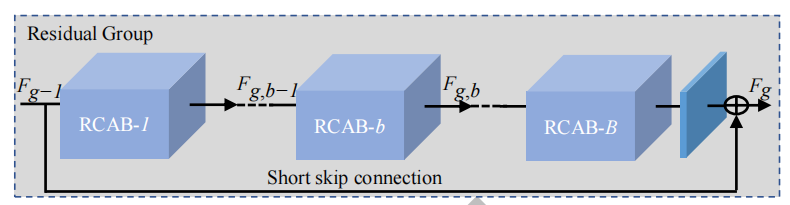
## Residual Group (RG)
class ResidualGroup(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(ResidualGroup, self).__init__()
modules_body = []
modules_body = [
RCAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(True), res_scale=1) \
for _ in range(n_resblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res整体RCAN层

## Residual Channel Attention Network (RCAN)
class RCAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(RCAN, self).__init__()
n_resgroups = args.n_resgroups
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
reduction = args.reduction
scale = args.scale[0]
act = nn.ReLU(True)
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# define head module
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
# RG层叠加
modules_body = [
ResidualGroup(
conv, n_feats, kernel_size, reduction, act=act, res_scale=args.res_scale, n_resblocks=n_resblocks) \
for _ in range(n_resgroups)]
modules_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
self.head = nn.Sequential(*modules_head)
self.body = nn.Sequential(*modules_body)
self.tail = nn.Sequential(*modules_tail)
def forward(self, x):
x = self.sub_mean(x) # 归一化处理
x = self.head(x) # 浅层特征提取
res = self.body(x) # RG群
res += x
x = self.tail(res) # 上采样模块,主要用了一个卷积和一个PixelShuffle
x = self.add_mean(x) # 反归一化
return x ![论文笔记——[CVPR 2020]Learning Spatial Attention for Face Super-Resolution](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220712212242-150x38.png)
![论文笔记——[SIGGRAPH2023]Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://blog.liguanxin.cn/wp-content/uploads/2023/05/微信截图_20230529202716-150x53.png)
![论文笔记——[人脸3d重建][CVPR 2021 Oral]Inverting Generative Adversarial Renderer for Face Reconstruction](https://blog.liguanxin.cn/wp-content/uploads/2022/11/微信截图_20221107142415-150x83.png)