创新点:
①把Transformer引入超分
②SwinIR由浅层特征提取、深度特征提取和高质量的图像重建三部分组成。
网络结构

①浅层特征提取:33卷积层
②深层特征提取采用K个residual Swin Transformer blocks (RSTB)以及一个33卷积层
③最后一个残差把恢复后的HQ加上原始的LQ
RSTB模块
由连续的SwinTransformer和残差连接构成。
Swin Transformer layers (STL)
第i个RSTB的特征F计算方式为(j表示第几个Swin Transformer layers):
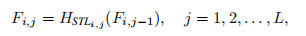
第i个RSTB的最后一层采用卷积,并且与当前RSTB的输入F(i,0)进行残差连接
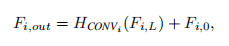
解释
浅层特征主要包含低频特征,深层特征用于恢复丢失的高频特征。低频通过长距离skip传输到恢复模块。
损失函数
采用L1范数计算像素损失
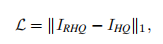
代码
class RSTB(nn.Module):
...
# 主要是在原版SwinTransformer的基础上套了一层卷积
def forward(self, x, x_size):
return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size), x_size))) + xclass SwinIR(nn.Module):
...
# 划分图像到patch
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# patch还原为图像
self.patch_unembed = PatchUnEmbed(
img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
...
# transformer操作
def forward_features(self, x):
x_size = (x.shape[2], x.shape[3])
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x, x_size)
x = self.norm(x) # B L C
x = self.patch_unembed(x, x_size)
return x
def forward(self, x):
H, W = x.shape[2:]
x = self.check_image_size(x)
self.mean = self.mean.type_as(x)
# 归一化
x = (x - self.mean) * self.img_range
if self.upsampler == 'pixelshuffle':
# for classical SR
# 浅层特征提取
x = self.conv_first(x)
# 深层特征提取,以及初始值的残差
x = self.conv_after_body(self.forward_features(x)) + x
x = self.conv_before_upsample(x)
# 基于sub-pixel的上采样来恢复SR图像
x = self.conv_last(self.upsample(x))
elif self.upsampler == 'pixelshuffledirect':
# for lightweight SR
x = self.conv_first(x)
x = self.conv_after_body(self.forward_features(x)) + x
x = self.upsample(x)
elif self.upsampler == 'nearest+conv':
# for real-world SR
x = self.conv_first(x)
x = self.conv_after_body(self.forward_features(x)) + x
x = self.conv_before_upsample(x)
x = self.lrelu(self.conv_up1(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
x = self.lrelu(self.conv_up2(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
x = self.conv_last(self.lrelu(self.conv_hr(x)))
else:
# for image denoising and JPEG compression artifact reduction
x_first = self.conv_first(x)
res = self.conv_after_body(self.forward_features(x_first)) + x_first
x = x + self.conv_last(res)
# 反归一化
x = x / self.img_range + self.mean
return x[:, :, :H*self.upscale, :W*self.upscale]![论文笔记——[人脸3d重建][CVPR 2021 Oral]Inverting Generative Adversarial Renderer for Face Reconstruction](https://blog.liguanxin.cn/wp-content/uploads/2022/11/微信截图_20221107142415-150x83.png)
![论文笔记——[CVPR 2020]Learning Spatial Attention for Face Super-Resolution](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220712212242-150x38.png)
![论文笔记——[CVPR2022]A ConvNet for the 2020s](https://blog.liguanxin.cn/wp-content/uploads/2022/06/微信截图_20220630121941-150x101.png)
![论文笔记——[NeurIPS 2021]Focal Self-attention for Local-Global Interactions in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220701221616-150x56.png)