创新点:
①由轻量CNN主干Lightweight CNN Backbone(LCB)和轻量Transformer主干Lightweight
Transformer Backbone(LTB)构成
②LCB可以动态调节特征图的大小,LTB是减少了计算量的Transformer结构
③设计了一个高频滤波模块(HFM)来捕获图像的纹理细节
网络结构

分为四部分:浅层特征提取、轻量CNN主干(LCB)、轻量Transformer主干(LTB)和图像重建
- 浅层特征提取:3*3卷积
- LCB:由多个高保真块HPB构成
高保真块HPB
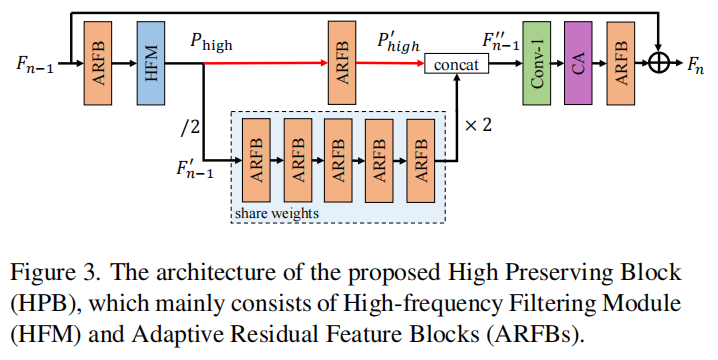
以前的SR网络通常会保持原分辨率不变,本文为了降低计算量,提出了一种新的高保真块(HPB)来降低特征的分辨率同时保留更多高频特征。HPB主要由高频滤波模块(HFM)和多个自适应残差特征块(ARFB)组成。
上方是通过HFM提取的高频特征,只经过一个ARFB。
下方是通过下采样后的低频特征。
高低频特征concat之后通过1*1卷积恢复原来的channel,最后经过一个通道注意力CA和ARFB,再加入残差稳定训练。
为了减少参数量,处理低频信息的ARFB共享相同的权重。
高频滤波模块HFM
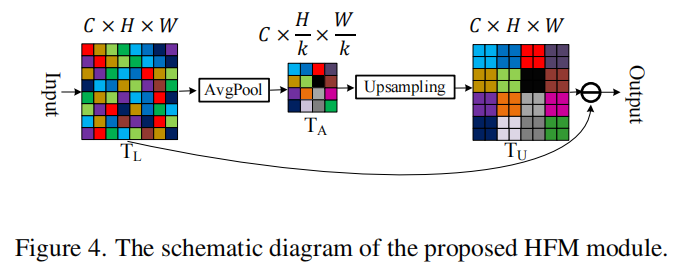
由于傅里叶变换很难嵌入到CNN中,于是本文提出了一种可微的高频滤波模块。
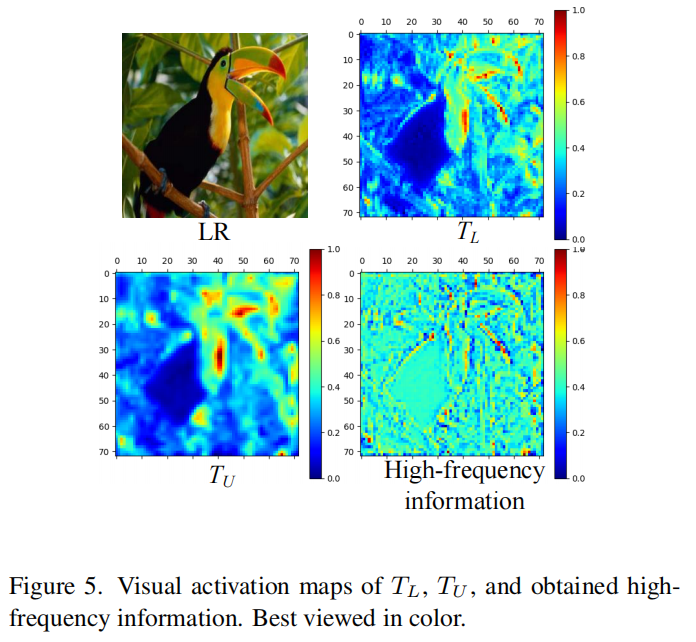
对于输入T_L,首先进行池化核为k的平均池化,然后T_A再上采样到原来的尺寸,T_U是作为与原始T_L相比更平滑的表达。最后,从T_L逐元素减去T_U,得到高频信息。
可视化效果:
自适应残差特征块ARFB
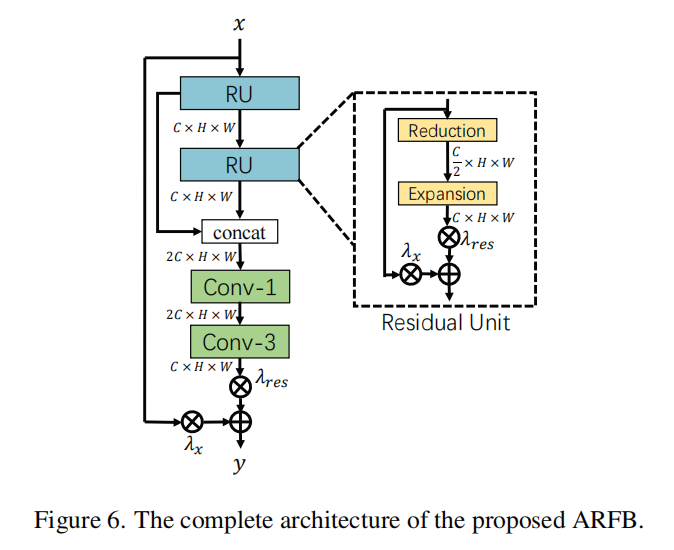
ARFB包含两个残差单元RU和两个卷积层。
为了减少参数量,RU由两个部分组成:减少和拓展,通过1*1卷积把channel减少一半,然后再还原到原来的大小。同时加入可学习参数\lambda_x来自适应调节残差的比例。
轻量Transformer主干
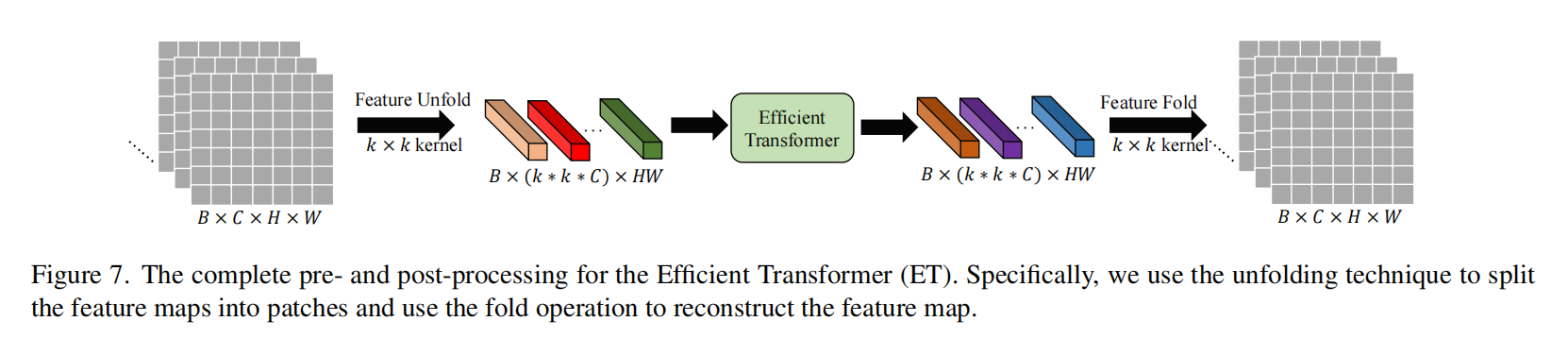
为了减少内存占用,本文提出一种轻量Transformer主干。
考虑到超分处理的是二维图像,在ViT中一维序列是通过非重叠的块划分生成的,这意味着每个块之间没有像素重叠。根据我们的实验,这些预处理方法并不适用于SISR。因此,本文提出了一种新的处理特征映射的处理方法。
如上图。通过k*k的核把每个像素拓展到k*k倍,来让像素获取到周边信息,同时也自动反映了每个patch的位置信息。
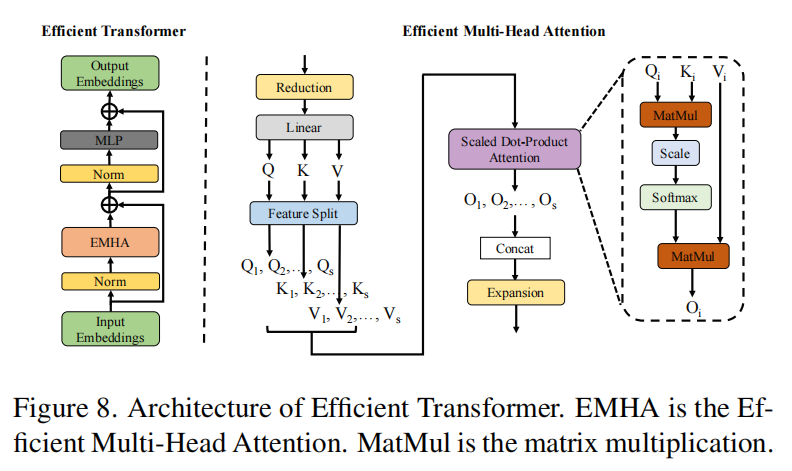
高效的多头注意力模块,占用更少的内存:考虑到图像通常具有较高的分辨率,导致N非常大,自注意矩阵的计算消耗了大量的GPU内存成本和计算成本。于是本文通过切割因子s,把QKV的N切割成了s份,每一份单独做自注意力,最后通过concat恢复原来的大小。
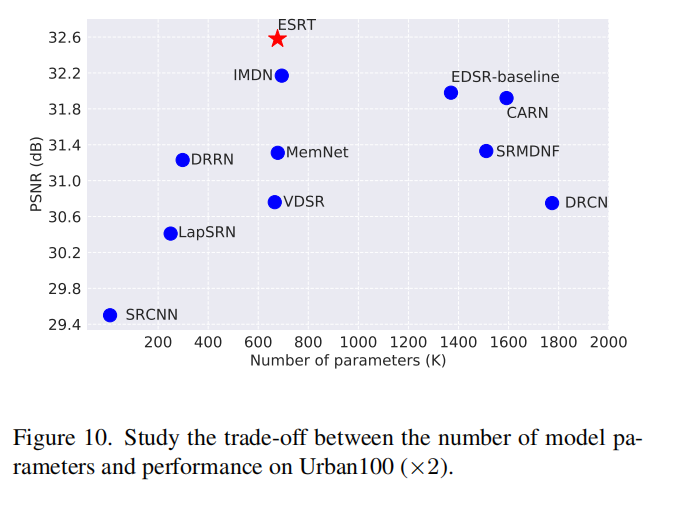
效果
本文方法的创新点很多,但是效果提升并不明显,甚至没和SwinIR比较。
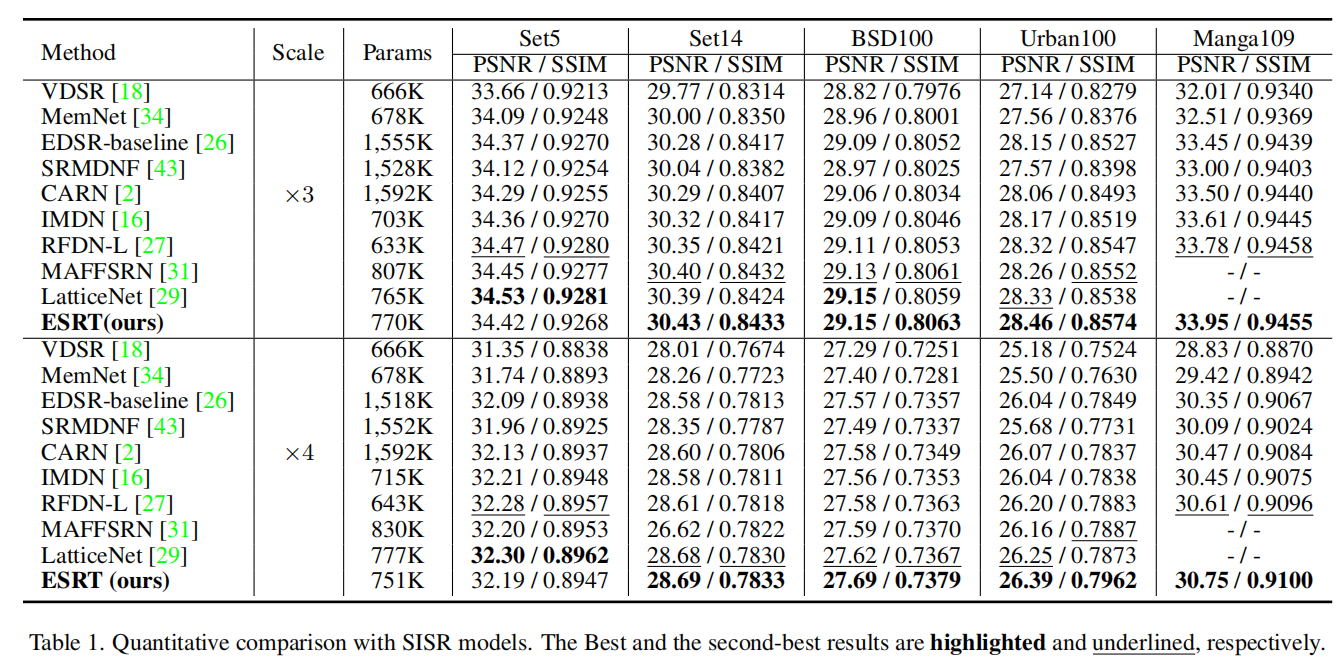
下面是用同样训练集训练的SwinIR

参数量
![论文笔记——[CVPR 2022]Vision Transformer with Deformable Attention](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220702214659-137x150.png)
![论文笔记——[CVPR 2022 Oral]Restormer: Efficient Transformer for High-Resolution Image Restoration](https://blog.liguanxin.cn/wp-content/uploads/2022/11/网络-150x72.png)
![论文笔记——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420151210-150x88.png)

![论文笔记——[人脸3d重建][CVPR 2021 Oral]Inverting Generative Adversarial Renderer for Face Reconstruction](https://blog.liguanxin.cn/wp-content/uploads/2022/11/微信截图_20221107142415-150x83.png)