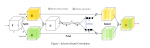
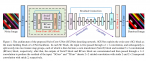
创新点:
①提出了一种自监督训练去噪模型的方法,可以在不需要干净目标的情况下训练
②只有一张噪声图像就可以训练(解决N2N需要一对噪声图像来训练的问题)
噪声图像的构成
\textbf{x} = \textbf{s} + \textbf{n},其中x为噪声图像,s为原始信号,n为信号退化噪声。一般来说,去噪任务是为了把n去除。
提出假设
- 信号s不是像素独立的(也即图像信号的像素不是相互独立的)。
- 噪声n在给定信号s的条件下是像素无关的(也就是各个像素之间的噪声是独立同分布的)。
- 噪声的均值为0
方法
作者认为去噪结果\hat{s}中的每一个像素只跟邻近的区域有关。于是提出
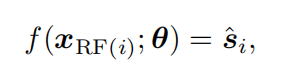
其中x_{RF(i)}代表以位置i为中心的一个patch,于是传统的监督学习可以表示为
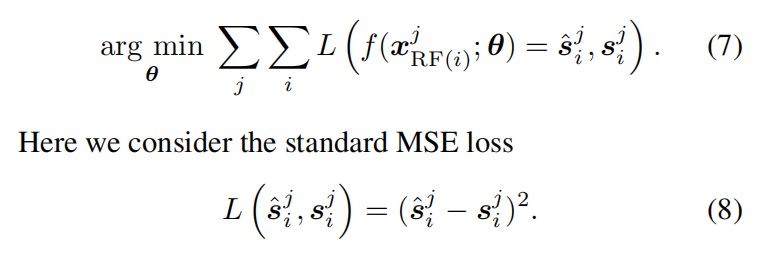
在N2V网络中,只有单张噪声图像,作者希望在一个patch范围内预测中心点的像素,但是如果把整个patch输入,网络只会直接把中心点输出。
于是作者提出了一种特殊的网络结构——盲点网络。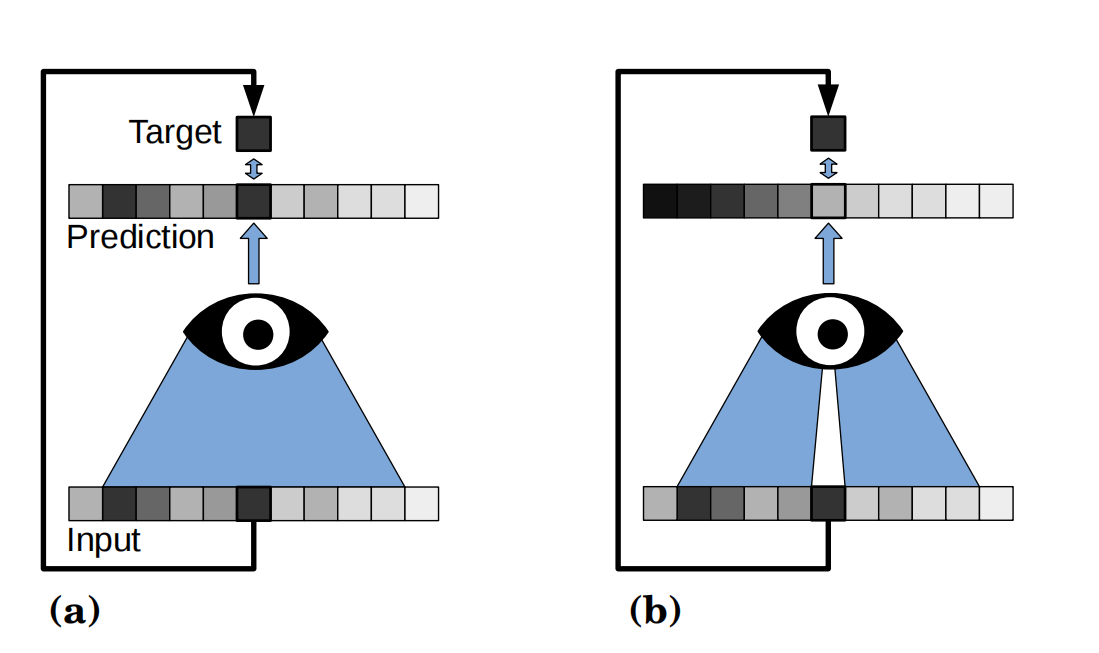
该网络的优点在于其不会学到恒等映射。因为我们假设了噪声在像素间是不相关的,所以只利用邻域信息是不能恢复噪声的,而只能恢复图像信息。也因此网络不能产生比期望值更好的估计结果。
当然,文章也提到了,由于该网络在预测时并没有使用所有可用信息,所以其结果精确度可能比起正常网络会有略微的下降。
在实际使用中,为了加快学习,并不会把中心像素变为空白,而是选择同一个patch里面中心的附近的一个像素替换中心像素。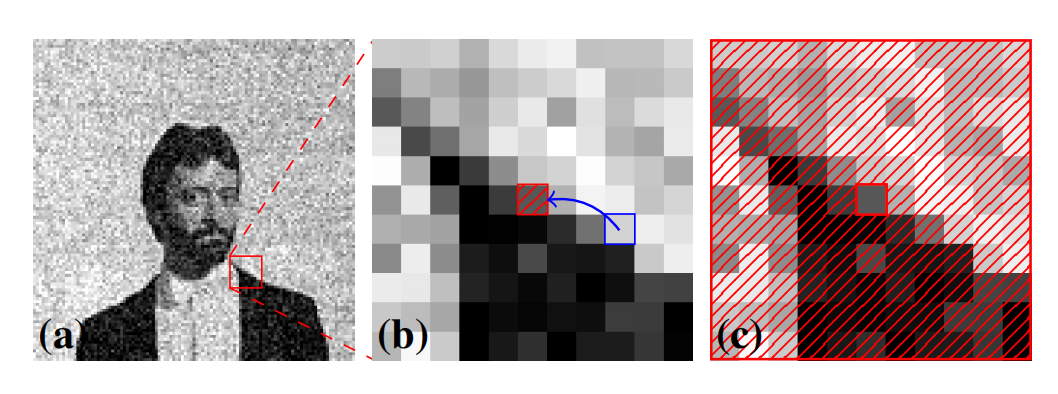
缺点:
①需要信号具有可预测性,否则会丢失纹理细节

②不能区分信号和结构性噪声,因为假设噪声是像素独立的

![论文笔记——[NeurIPS 2021]Focal Self-attention for Local-Global Interactions in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220701221616-150x56.png)
![论文笔记——[SIGGRAPH2023]Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://blog.liguanxin.cn/wp-content/uploads/2023/05/微信截图_20230529202716-150x53.png)
![论文笔记——[CVPR 2022 Oral]Restormer: Efficient Transformer for High-Resolution Image Restoration](https://blog.liguanxin.cn/wp-content/uploads/2022/11/网络-150x72.png)