创新点:
①提出一种盲点到无盲点的训练方法(解决N2V中信息缺失的问题)
②可以避免去噪过程中的“恒等映射”问题(噪点像素被直接输出)
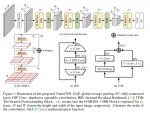
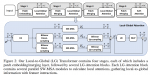
模型架构
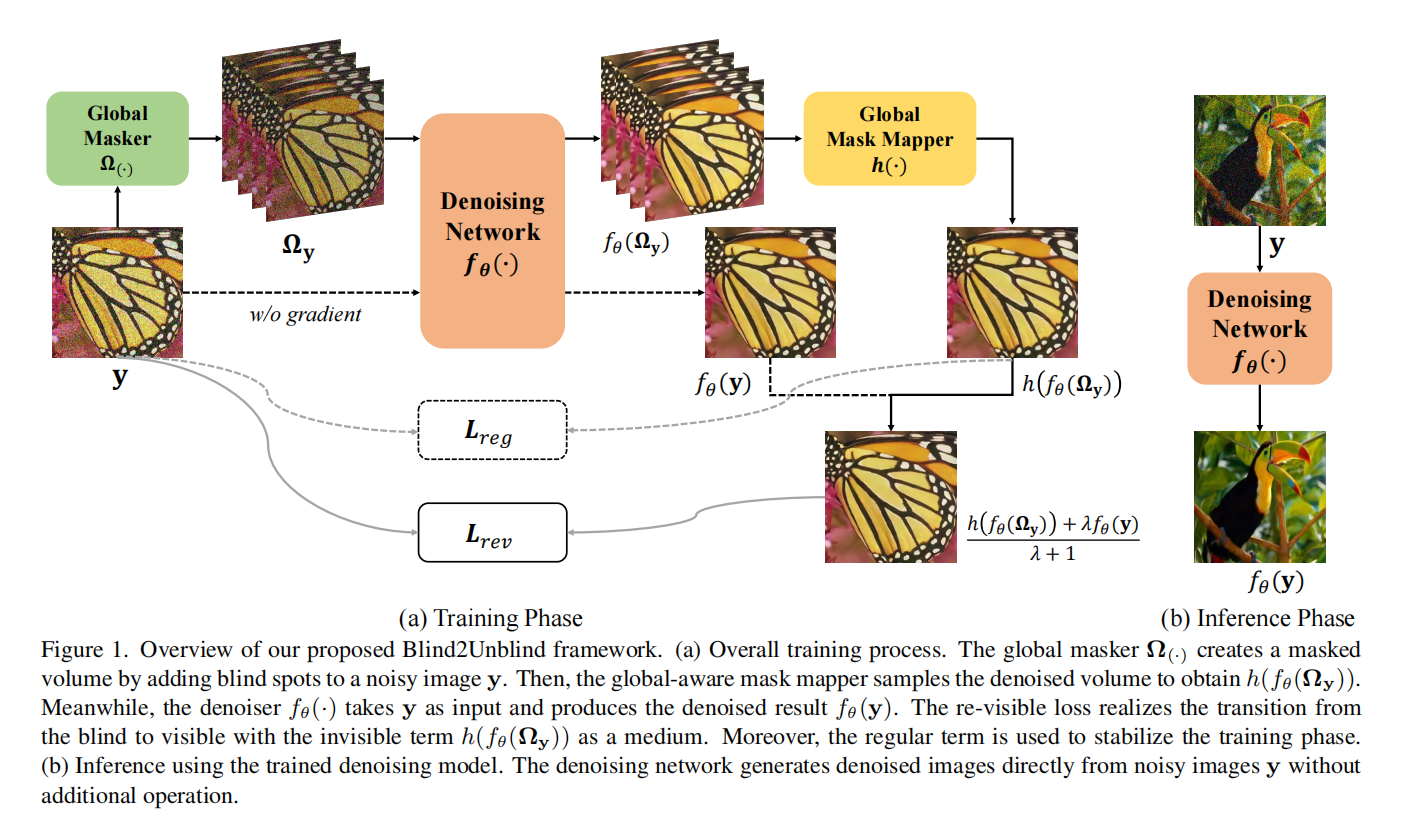
一张噪声图像y通过一个Global Masker Ω操作,变成四张含有盲点的图片,这四张图片分别通过去噪网络f(),获得四张去噪结果,然后通过Global Mask Mapper h()的操作,获得一张去噪结果h(f_\Theta(\Omega_y))。另一方面,完整的噪声图像y也要通过去噪神经网络f(),获得另一个去噪结果f_\Theta(y)。两者进行一个加权平均,获得的结果和y做loss,即L_{rev}。
损失函数为:
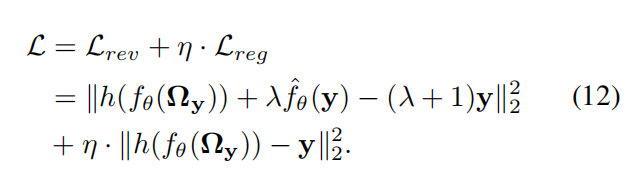
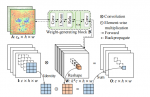
Global-Aware Mask Mapper
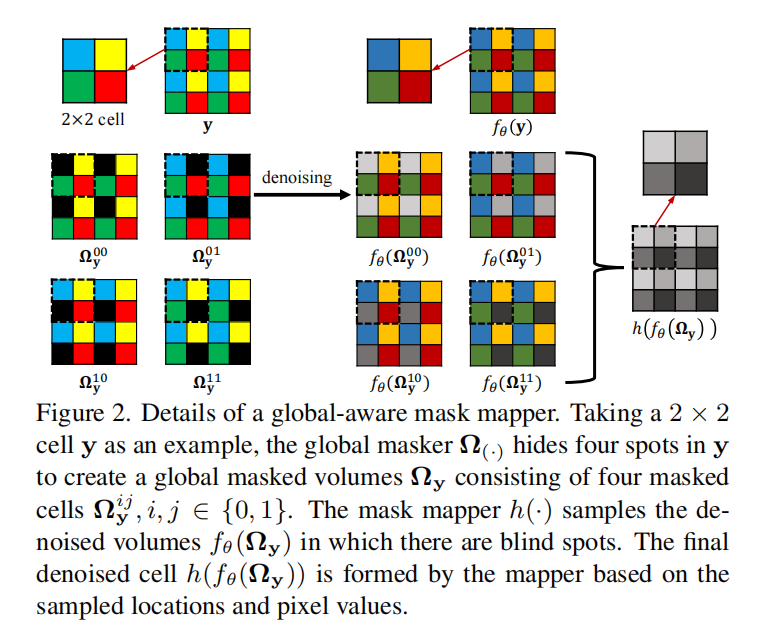
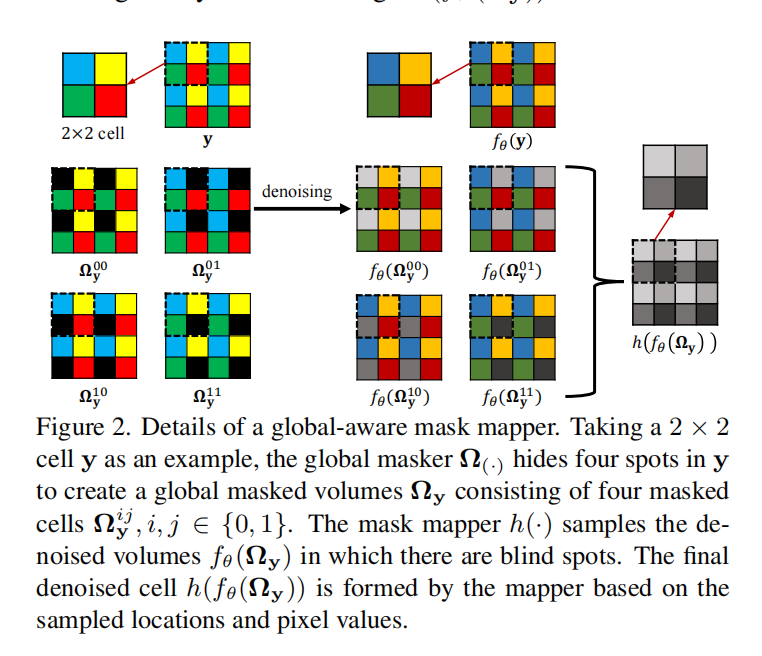
把图像分成若干2×2的窗口,每个窗口把一个位置的像素置为黑色,输出四张mask后的噪声图,分别输入去噪网络,最后把各个恢复的部分合并为不含盲点的复原图像。
推理阶段
如第一张图,推理阶段只使用去噪网络进行去噪。
实验结果
作者做了合成图像去噪和真实图像去噪,部分情况下指标不是最高。

CODE
代码整体采用UNet结构
# Noise adder(噪声产生模块)
noise_adder = AugmentNoise(style=opt.noisetype)
# Masker(全局感知掩模映射器)
masker = Masker(width=4, mode='interpolate', mask_type='all')
# Network
network = UNet(in_channels=opt.n_channel,
out_channels=opt.n_channel,
wf=opt.n_feature)![论文笔记——[ICCV 2021 Oral]Co-Scale Conv-Attentional Image Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220713171240-138x150.png)
![论文笔记——[AAAI 2022]Less is More: Pay Less Attention in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220720201734-150x70.png)
6666