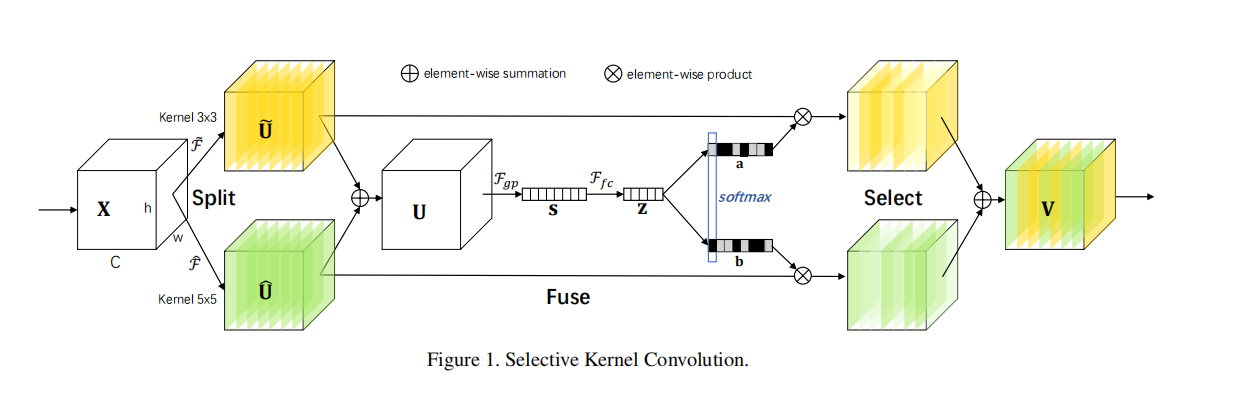
sknet是一个卷积结构,可以扩大卷积的感受野,并且能让卷积同时捕获到3*3和5*5的特征。
整体结构
CODE
sknet的主体分为4个stage,每个stage由多个SKUnit构成
class SKNet(nn.Module):
def __init__(self, class_num, nums_block_list = [3, 4, 6, 3], strides_list = [1, 2, 2, 2]):
super(SKNet, self).__init__()
self.basic_conv = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(3,2,1)
self.stage_1 = self._make_layer(64, 128, 256, nums_block=nums_block_list[0], stride=strides_list[0])
self.stage_2 = self._make_layer(256, 256, 512, nums_block=nums_block_list[1], stride=strides_list[1])
self.stage_3 = self._make_layer(512, 512, 1024, nums_block=nums_block_list[2], stride=strides_list[2])
self.stage_4 = self._make_layer(1024, 1024, 2048, nums_block=nums_block_list[3], stride=strides_list[3])
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Linear(2048, class_num)
# 构造每一个stage,包含多个SKUnit,每一层数量通过nums_block_list来定
def _make_layer(self, in_feats, mid_feats, out_feats, nums_block, stride=1):
layers=[SKUnit(in_feats, mid_feats, out_feats, stride=stride)]
for _ in range(1,nums_block):
layers.append(SKUnit(out_feats, mid_feats, out_feats))
return nn.Sequential(*layers)
def forward(self, x):
fea = self.basic_conv(x) # 浅层特征提取
fea = self.maxpool(fea) # 最大池化层使图片尺寸长宽各减少两倍
# 各个stage
fea = self.stage_1(fea)
fea = self.stage_2(fea)
fea = self.stage_3(fea)
fea = self.stage_4(fea)
# 自适应平均池化层对各个channel求均值,,然后squeeze和classifier使得fea变成class_num个分类
fea = self.gap(fea)
fea = torch.squeeze(fea)
fea = self.classifier(fea)
return feaSKUnit单元,让包括SKConv前后的卷积归一等操作
class SKUnit(nn.Module):
def __init__(self, in_features, mid_features, out_features, M=2, G=32, r=16, stride=1, L=32):
super(SKUnit, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_features, mid_features, 1, stride=1, bias=False),
nn.BatchNorm2d(mid_features),
nn.ReLU(inplace=True)
)
self.conv2_sk = SKConv(mid_features, M=M, G=G, r=r, stride=stride, L=L)
self.conv3 = nn.Sequential(
nn.Conv2d(mid_features, out_features, 1, stride=1, bias=False),
nn.BatchNorm2d(out_features)
)
self.shortcut = nn.Sequential()
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.conv1(x) # 1*1卷积,batchnorm,relu层
out = self.conv2_sk(out) # SKConv层
out = self.conv3(out) # 1*1卷积,batchnorm
return self.relu(out + self.shortcut(residual))最核心的SKConv层,如图所示
class SKConv(nn.Module):
def __init__(self, features, M=2, G=32, r=16, stride=1 ,L=32):
super(SKConv, self).__init__()
d = max(int(features/r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3, stride=stride, padding=1+i, dilation=1+i, groups=G, bias=False),
nn.BatchNorm2d(features),
nn.ReLU(inplace=True)
))
self.gap = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Sequential(nn.Conv2d(features, d, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=True))
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Conv2d(d, features, kernel_size=1, stride=1)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0] # 获取batch_size
feats = [conv(x) for conv in self.convs] # 让x分成3*3和5*5进行卷积
feats = torch.cat(feats, dim=1) # 合并卷积结果
feats = feats.view(batch_size, self.M, self.features, feats.shape[2], feats.shape[3]) # reshape一下大小
# 接下来计算图中的U
feats_U = torch.sum(feats, dim=1) # 两个分支得到的卷积结果相加
feats_S = self.gap(feats_U) # 自适应池化,也就是对各个chanel求均值得到图中的S
feats_Z = self.fc(feats_S) # fc层压缩特征得到图中的Z
attention_vectors = [fc(feats_Z) for fc in self.fcs] # 不同的头各自恢复特征Z到channel的宽度
attention_vectors = torch.cat(attention_vectors, dim=1) # 连接起来方便后续操作
attention_vectors = attention_vectors.view(batch_size, self.M, self.features, 1, 1) # reshape起来方便后续操作
attention_vectors = self.softmax(attention_vectors) # softmax得到图中的a和b(实际上是联合在了第二维)
feats_V = torch.sum(feats*attention_vectors, dim=1) # 把softmax后的各自自注意力跟卷积后的结果相乘,得到图中select的结果,然后相加得到最终输出
return feats_V
![论文笔记——[CVPR2022]A ConvNet for the 2020s](https://blog.liguanxin.cn/wp-content/uploads/2022/06/微信截图_20220630121941-150x101.png)
![论文笔记——[AAAI 2022]Less is More: Pay Less Attention in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220720201734-150x70.png)
![论文笔记——[ICCV 2021]Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220725143207-150x86.png)
![论文笔记——[CVPR 2020]Learning Spatial Attention for Face Super-Resolution](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220712212242-150x38.png)