MinHash(最小哈希)是一种用于估算集合相似性的算法,它常用于处理大规模数据集的去重问题,尤其是当数据集非常大,无法一次性加载到内存中时。MinHash 主要应用于文本数据的相似度计算,例如文档去重、网页索引、垃圾邮件检测等场景。
MinHash是基于Jaccard Index相似度(海量数据不可行)的算法,一种降维的方法。
Jaccard相似度
Jac(X,Y) = |X∩Y| / |X∪Y|
MinHash 的基本原理
在A∪B这个大的随机域里,选中的元素落在A∩B这个区域的概率,这个概率就等于Jaccard的相似度。
步骤
1、创建哈希函数:
选择一组哈希函数h1, h2,…, hn,这些函数将集合中的元素映射到一个固定范围的整数。哈希函数应该满足均匀分布的要求。
2、生成候选签名:
对于每个集合S,使用每个哈希函数hi,计算集合S中所有元素的哈希值,并选取最小的哪个哈希值作为该哈希函数对应于集合S的候选签名。
3、构造签名矩阵:
对于每个哈希函数 hi,构造一个签名矩阵,矩阵的行对应哈希函数,列对应各个集合。矩阵中的每个元素代表一个集合经过哈希函数处理后的候选签名。
4、估计 Jaccard 相似度:
Jaccard 相似度是两个集合的交集大小除以并集大小。通过比较两个集合的签名矩阵中的行,可以估计它们之间的 Jaccard 相似度。如果两个集合的签名在某一行相同,那么这一行对应的哈希函数计算出的最小哈希值也是相同的,这暗示了这两个集合可能是相似的。
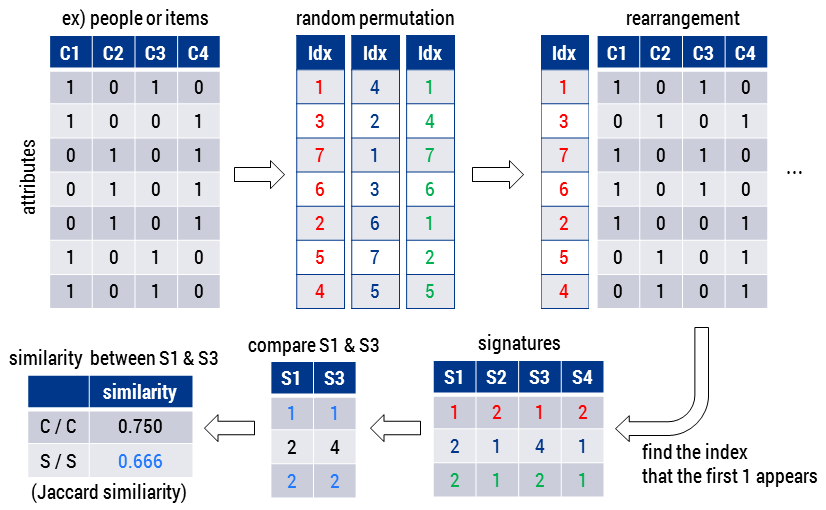
大规模数据去重
步骤:
1、构造签名矩阵
- 对于每条记录,提取特征(如文档中的单词),并为每个特征计算哈希值。
- 使用一组预先选定的哈希函数为每条记录生成签名。
2、估计相似度:
- 比较不同记录的签名,如果两条记录的签名在多个位置相同,那么这两条记录可能是重复的。
- 可以设定一个阈值来判断哪些记录被认为是重复的。
3、过滤重复项:
根据相似度估计的结果,过滤掉那些被认为是重复的记录。
MinHash仍然需要遍历所有的集合对,因此通常与LSH一起用。
LSH
其基本思路是将相似的集合聚集到一起,减小查找范围,避免比较不相似的集合。
1、LSH将原signature matrix按行划分成多个band,每个band的宽度是r,显然有b*r=num of hash function for MinHash,然后对band内每个signature段hash,形成多个桶。
2、两个文档作为候选匹配的充要条件是至少有一个band的hash在同一个桶中
通过分段hash然后再对在一个桶中的候选signature进行相似度计算,这种方式可以在一定程度上保留对相似度的估计,同时大幅提升计算的效率(因为只需要匹配部分文档)。
