4月 1, 2022
论文笔记——Transformer in Convolutional Neural Networks
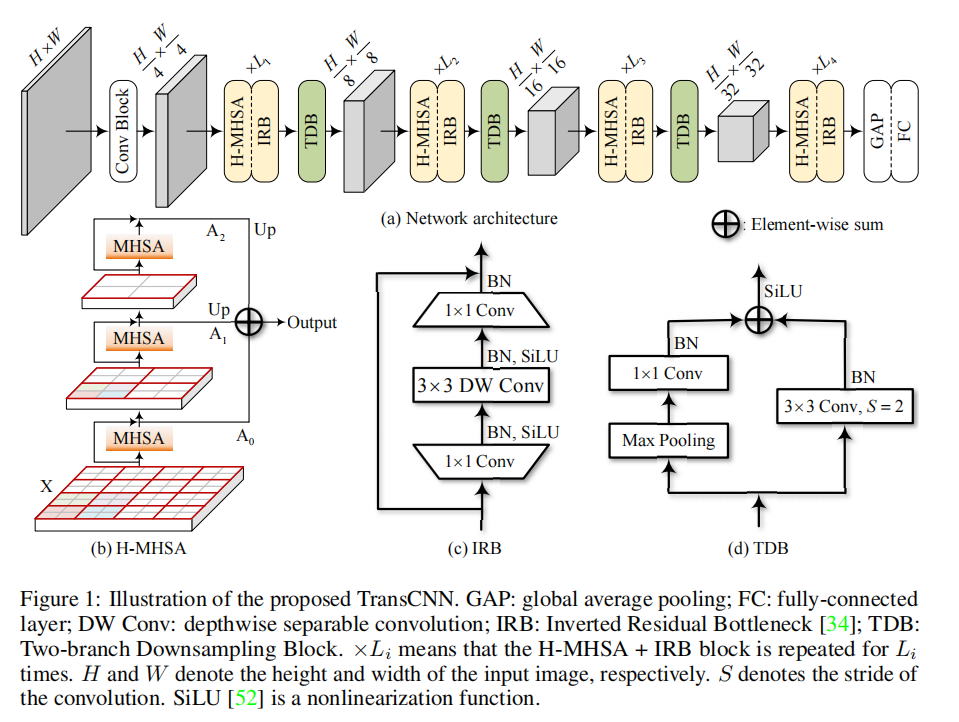
创新点: ①层次多头自注意力机制,减少计算/空间复杂度 ②结合了transformer和CNN的优势 总体结构 GAP:全局平均池化 FC:全连接层 DW Co...
1755 1
3月 31, 2022
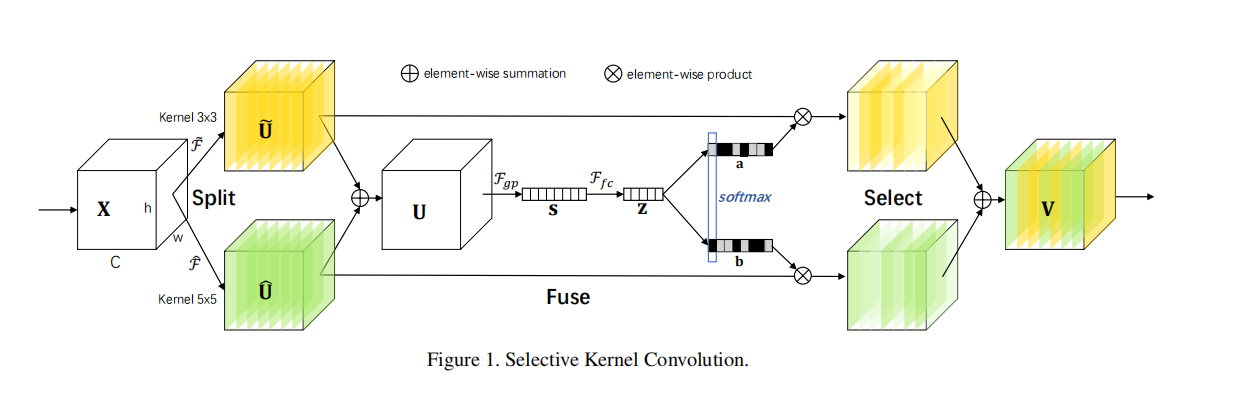
sknet是一个卷积结构,可以扩大卷积的感受野,并且能让卷积同时捕获到[katex]3*3[/katex]和[katex]5*5[/katex]的特征。 整体结...
2141 0
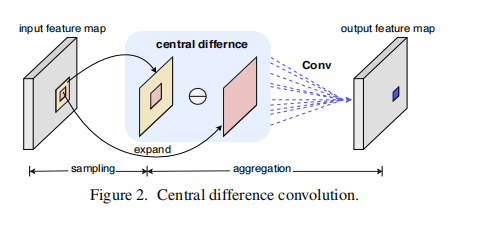
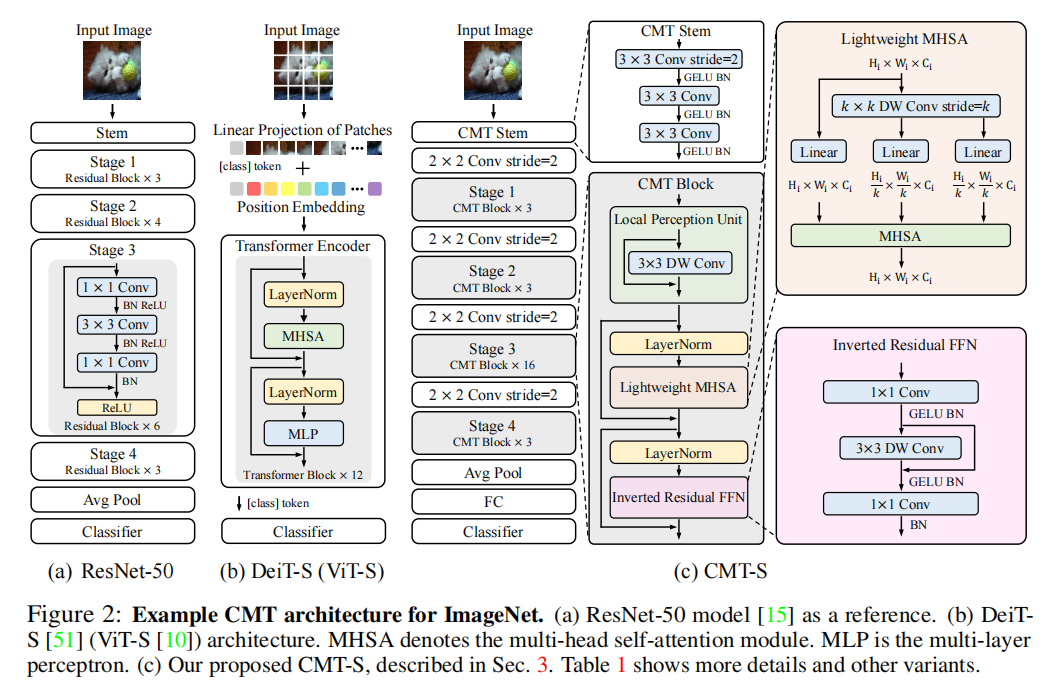
3月 27, 2022
创新点: ①提升性能,相比ViT-S参数更少的情况下精度更高 ②transformer和CNN的混合网络,利用transformer来捕获远程特征关系,CNN捕...
1982 0
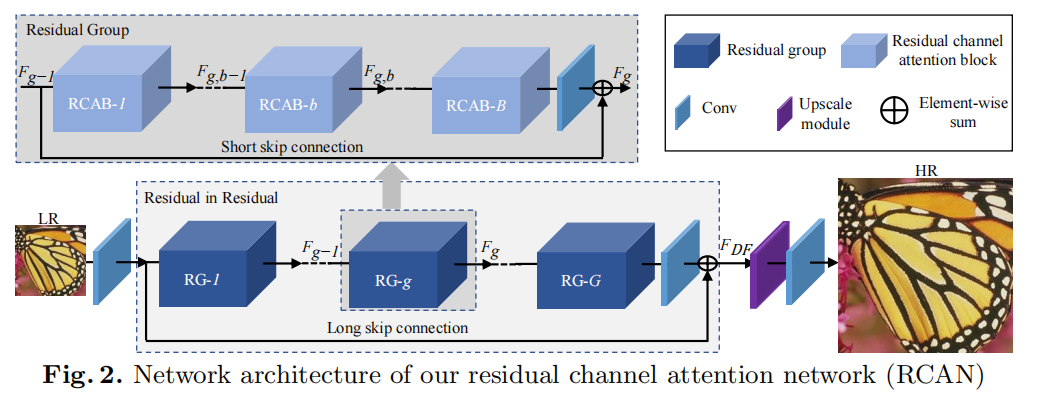
3月 25, 2022
创新点: (1)非常深的残差通道注意网络(RCAN),用于高精度的图像SR。我们的RCAN可以比以前的基于cnn的方法更深入,并获得更好的SR性能。 (2)残差...
1708 0
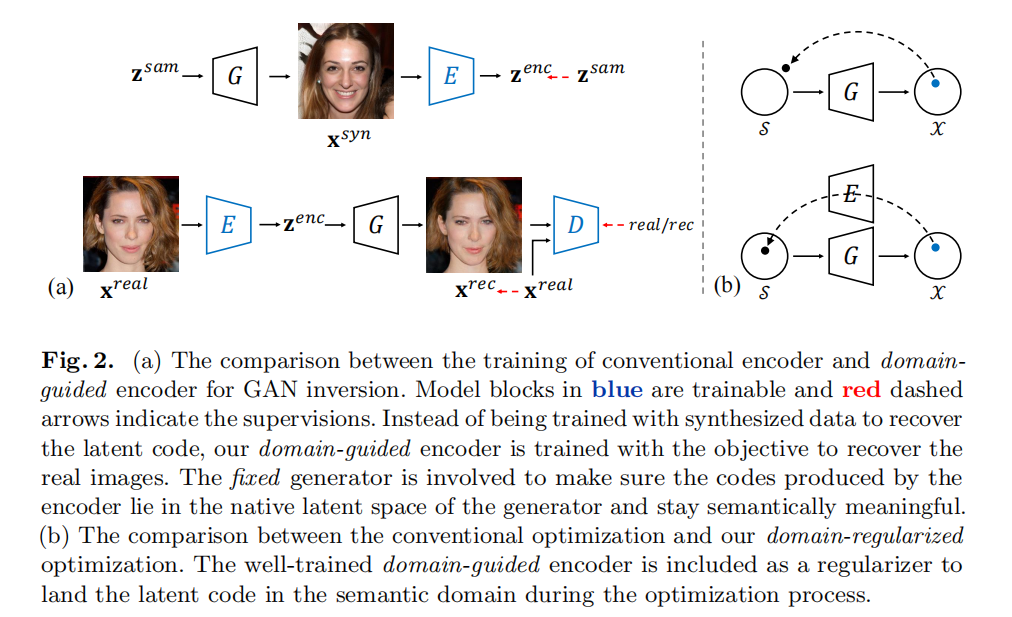
3月 20, 2022
一个对于图像生成GAN逆转域的研究(GAN反演) 以前方法存在的问题:只能把图像逆转为像素,而不是原始的潜在空间(latent space) 创新点: ①可以在...
1990 0
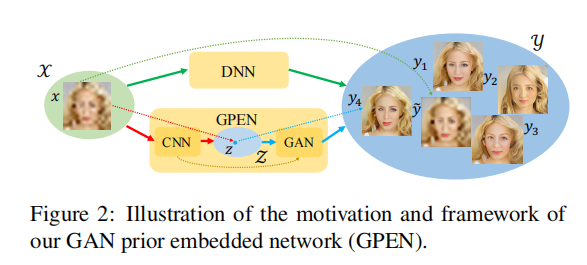
3月 19, 2022
创新点: ①训练一个生成高质量人脸的GAN网络,然后放到U型结构的解码侧,再通过低分辨率图像输入U型结构中进行微调(以前的工作没有微调,指pixel2style...
1924 1
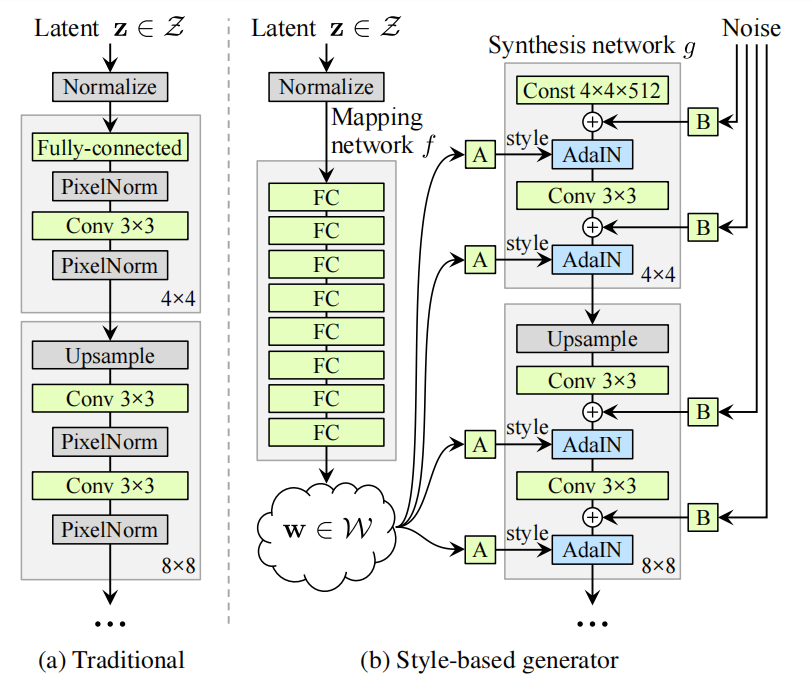
3月 19, 2022
StyleGAN StyleGAN是由Nvidia研究人员于2018年12月推出的生成对抗网络,并于2019年2月可用。 StyleGAN依赖于Nvidia的C...
1978 0
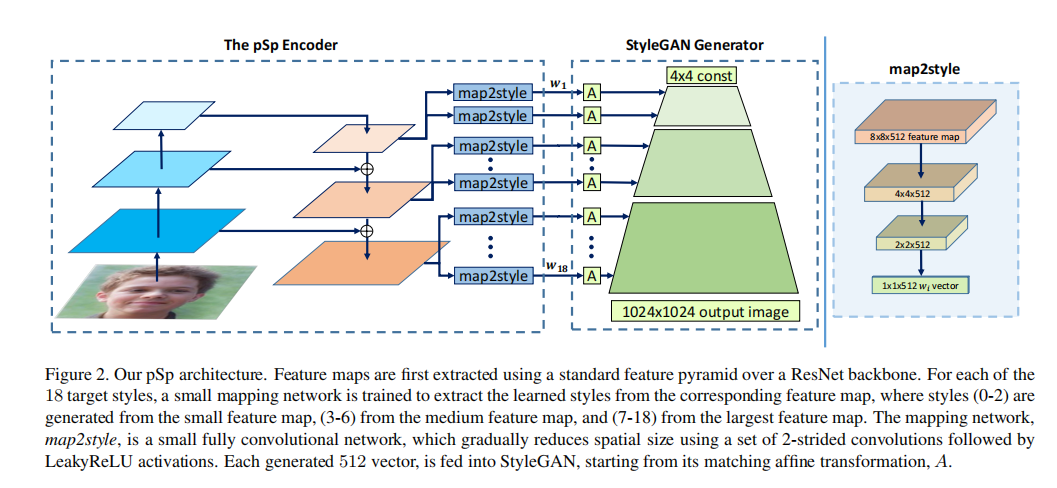
3月 19, 2022
创新点: ①新的编码器结构,把图像投影到W+空间(与以往的先还原图像,再编辑不同,本方法在W+空间中编辑)。 ②证明了图像的W空间,可以提供控制和编辑的能力 ③...
2038 0


3月 16, 2022
创新点: ①把Transformer引入超分 ②SwinIR由浅层特征提取、深度特征提取和高质量的图像重建三部分组成。 网络结构 ①浅层特征提取:33卷积层 ②...
1894 0
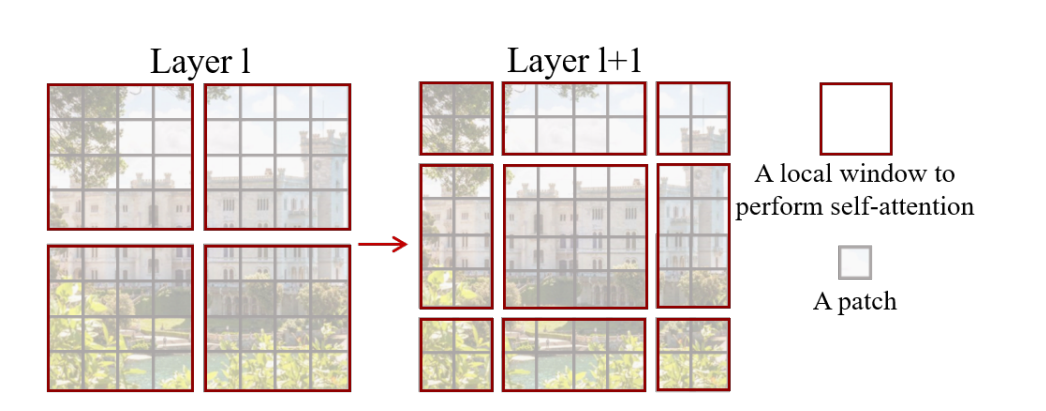
3月 16, 2022
创新点: ①把transformer引入计算机视觉 ②把transformer中多头自注意力(MSA)模块替换成基于滑动窗口的模块 滑动窗口机制 红框窗口表示一...
1692 0
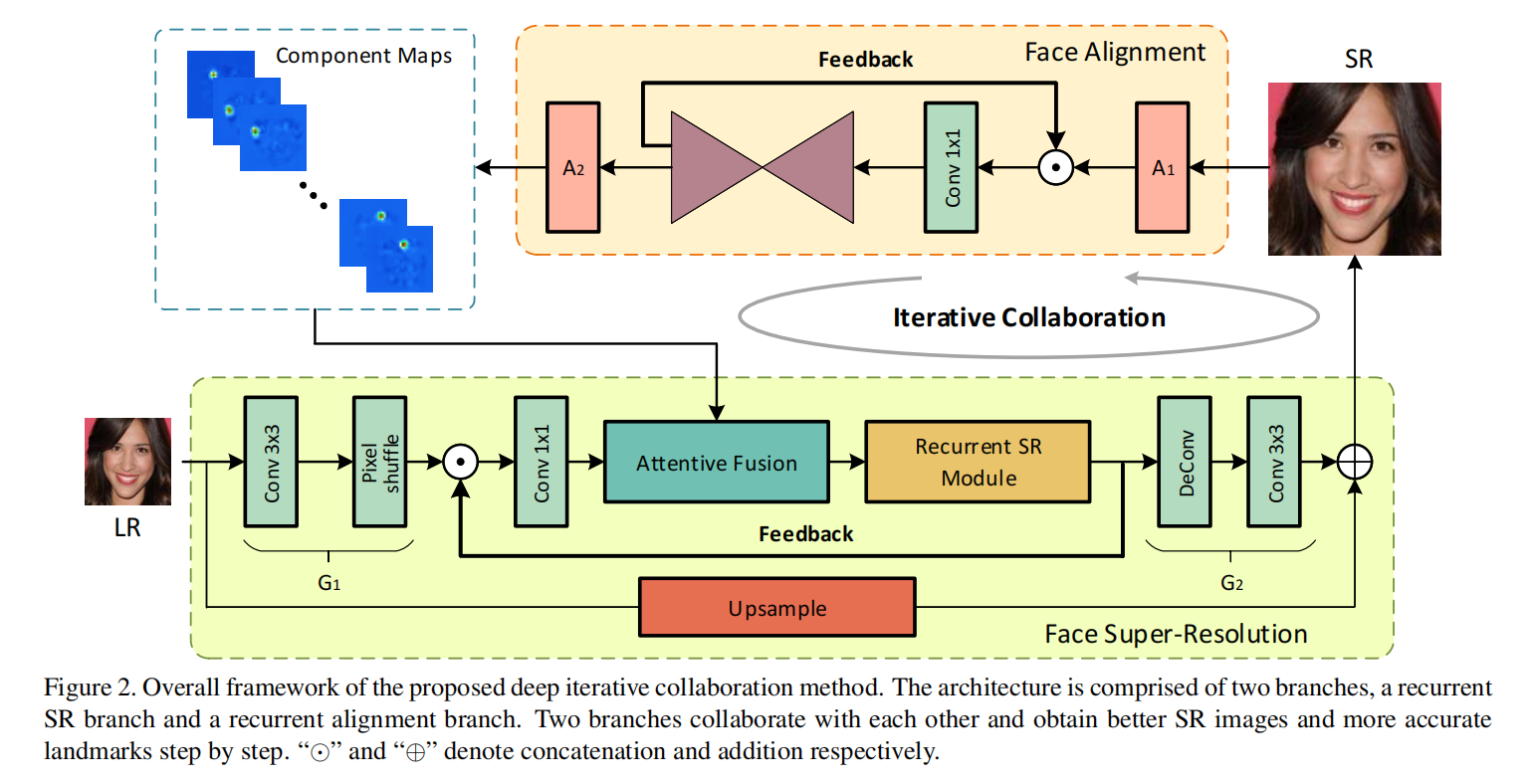
3月 15, 2022
创新点: ①两个循环协作的网络,一个恢复图像,一个评估landmark ②注意力融合模块 解决的痛点:通过低分辨率图片 LR 或者粗超分辨率图片 SR 得到的人...
1513 0
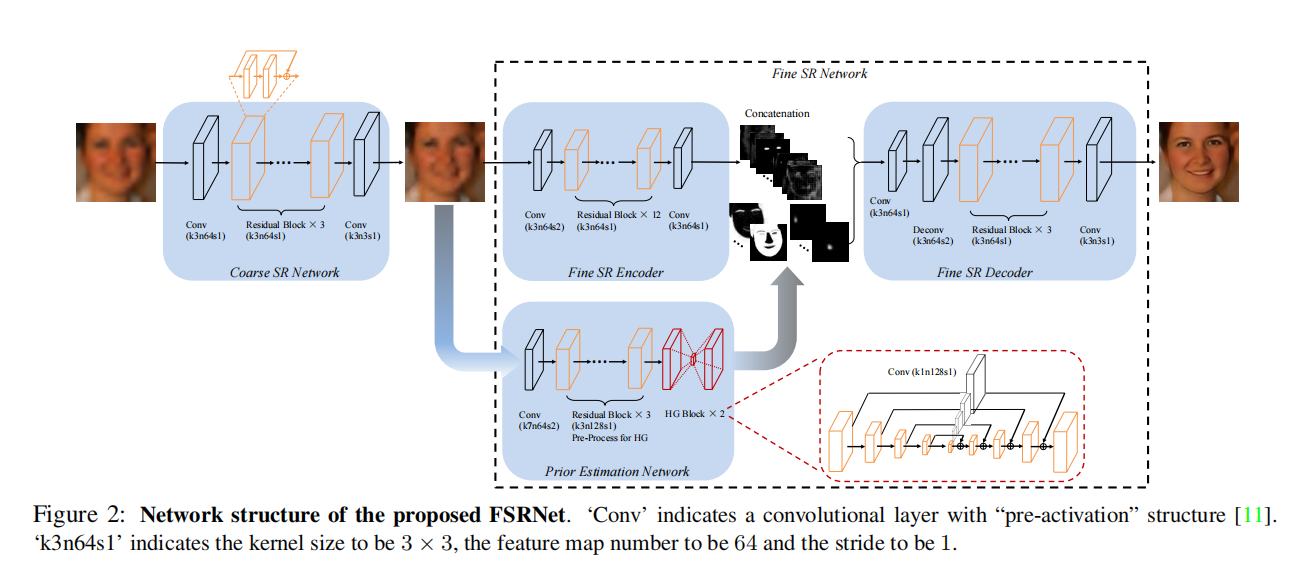
3月 11, 2022
创新点: ①利用几何先验,即面部地标热图和解析图 ②引入对抗性网络(FSRGAN) 总体流程:先经过一个网络来恢复粗糙图像,然后进入两个分支分别是精细的SR编码...
1662 0
3月 10, 2022
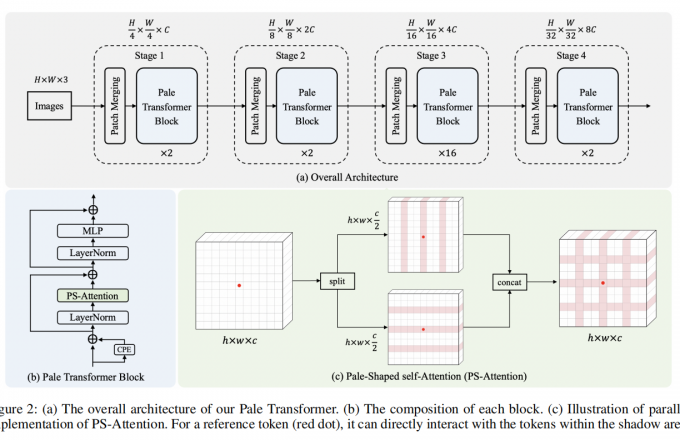
创新点:以ViT作为backbone,提出了一种在Pale-Shaped内进行自注意力的结构,能显著降低计算和记忆成本 首先将输入特征图在空间上分割成多个Pal...
1615 0
3月 10, 2022
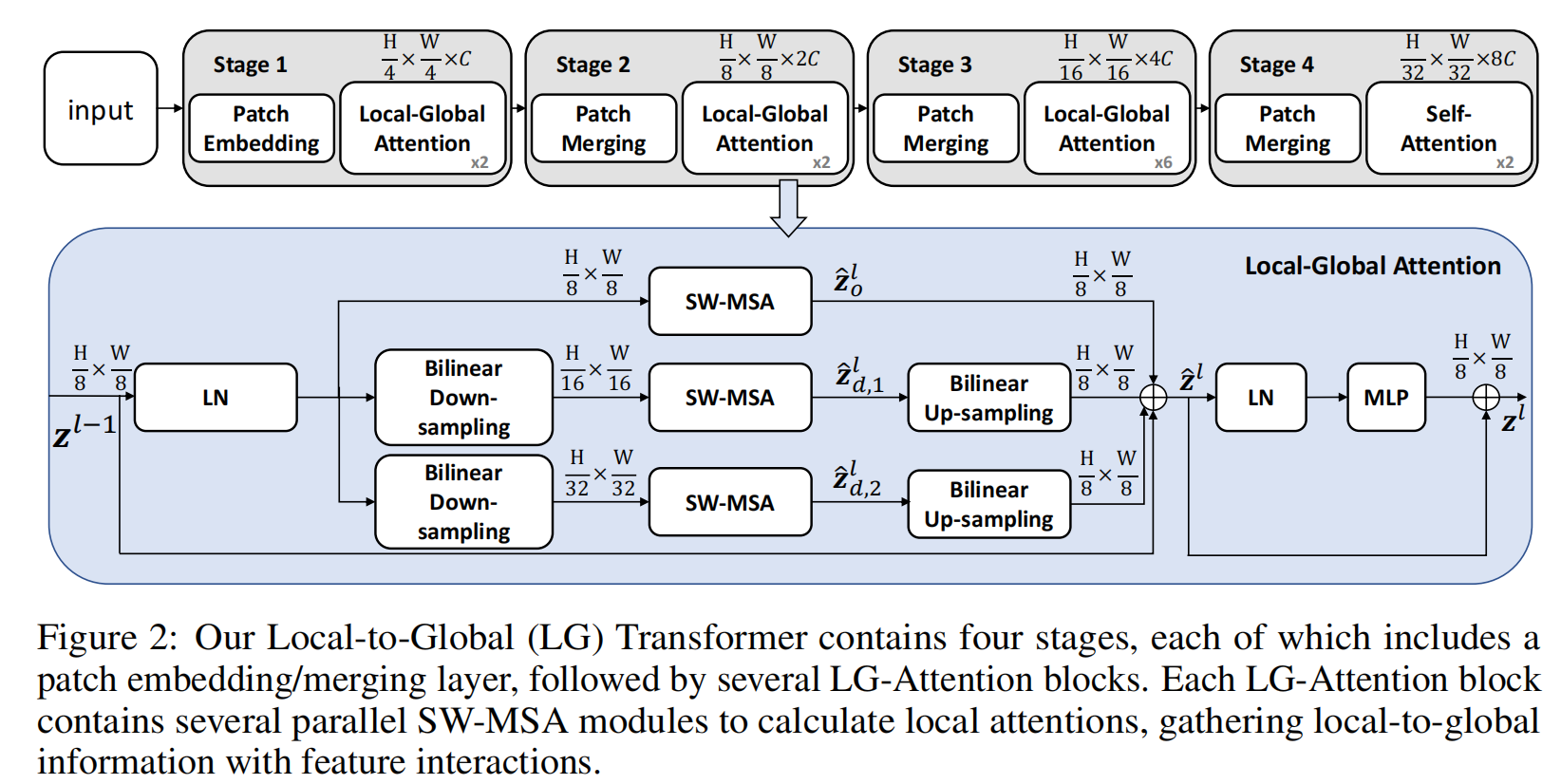
创新点: ①多尺度图像多路径的Transformer,最后汇总以保证局部和全局特征提取 ②每个stage多粒度从局部到整体的推理 CNN的多粒度连接: 每个阶段...
1573 0
3月 10, 2022
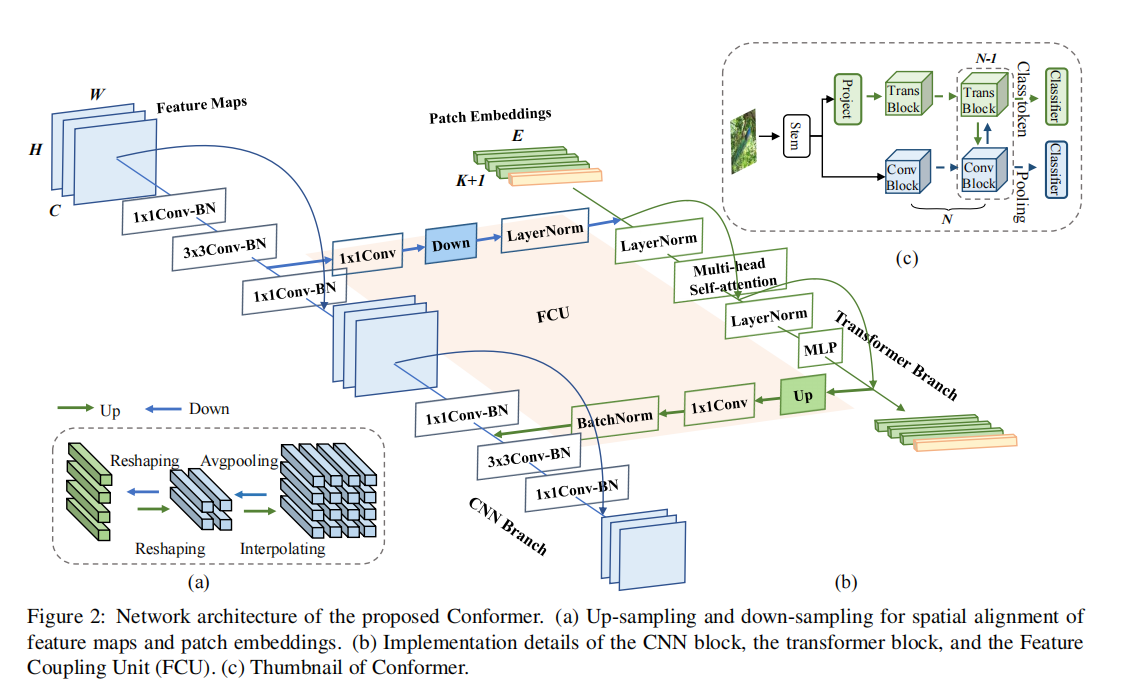
创新点:同时利用CNN的捕获局部特征的优点和Transformer捕获长距离特征的优点。 上图中的(c)表示整个网络结构的并发构型。 (b)表示,两个分支的初始...
1694 0

3月 1, 2022
RAS即“Reverse Attention-Based Residual Network for Salient Object Detection”,是一个图...
1707 0