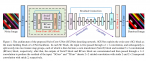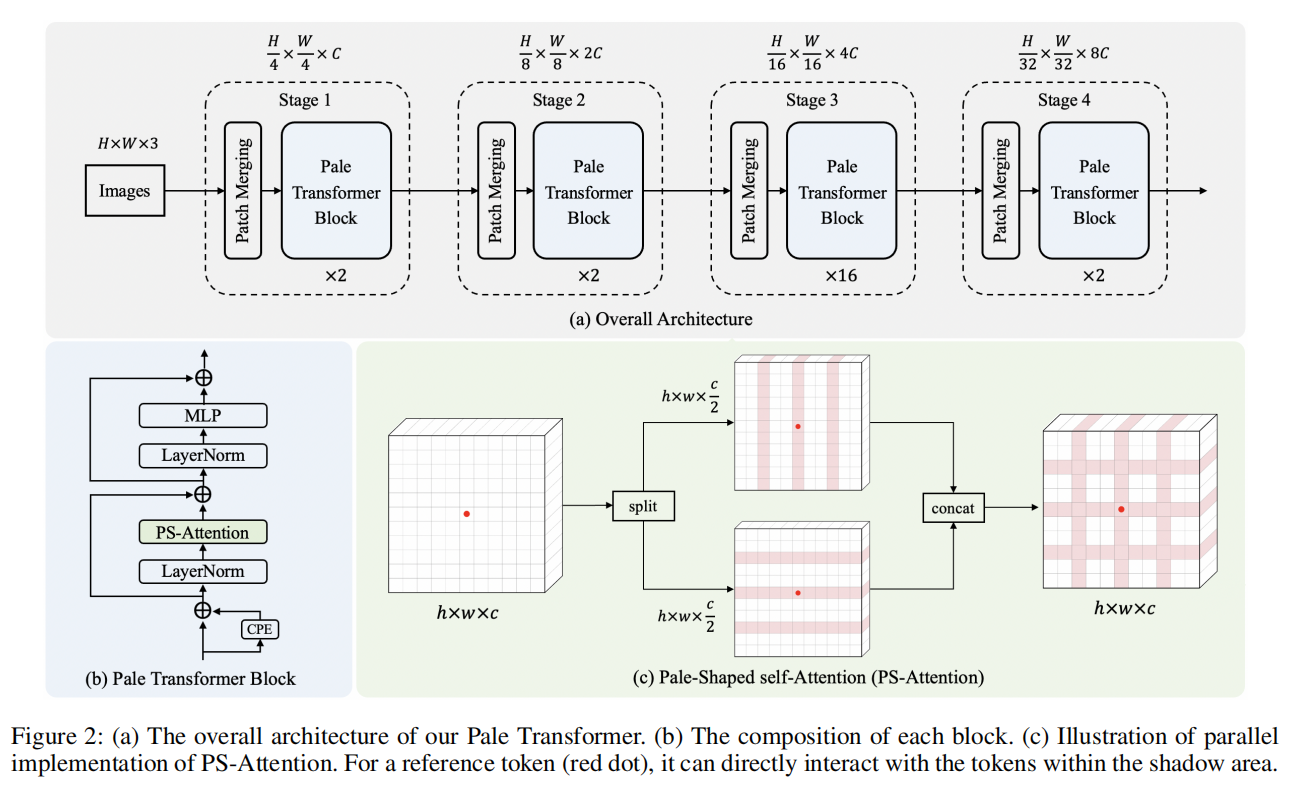

创新点:以ViT作为backbone,提出了一种在Pale-Shaped内进行自注意力的结构,能显著降低计算和记忆成本
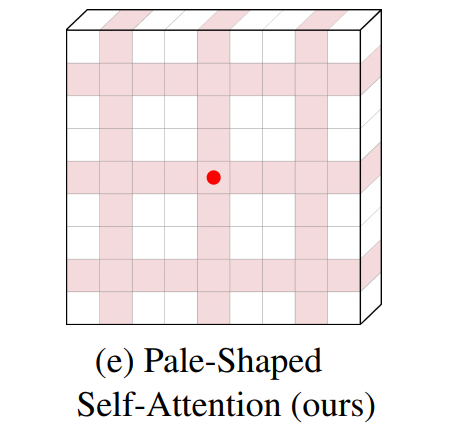
- 首先将输入特征图在空间上分割成多个Pale-Shaped的区域。每个Pale-Shaped区域(缩写为Pale)由特征图中相同数量的交错行和列组成。相邻行或列之间的间隔对于所有的Pale是相等的。
- 然后,在每个Pale区域内进行Self-Attention计算。对于任何Token,它都可以直接与同一Pale中的其他Token交互,这使得本文的方法能够在单个PS-Attention层中捕获更丰富的上下文信息。
高效的并行实现
为了进一步提高效率,将上面提到的普通PS-Attention分解为行注意和列注意,它们分别在行Token组和列Token组内执行自注意力。
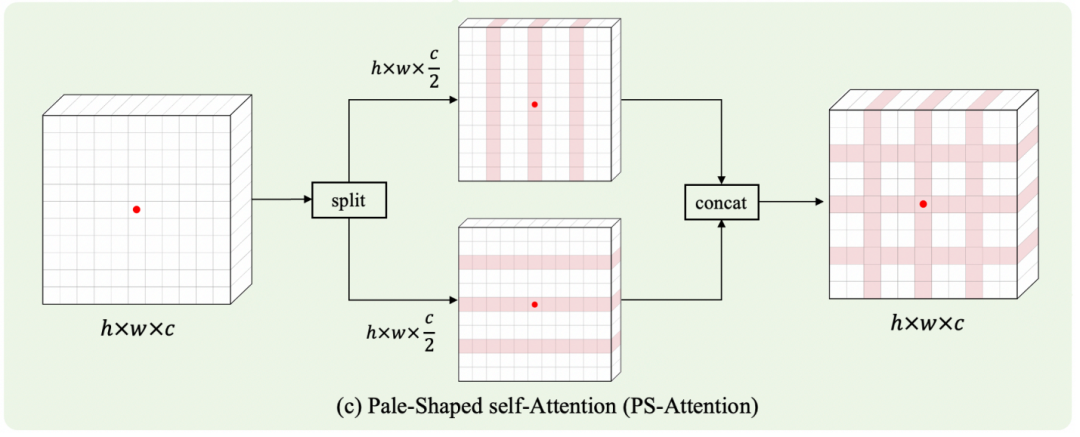
如(c),首先将输入特征划分为两个独立的部分和,然后将其分为多个组,以便分别按行和列进行注意力计算。
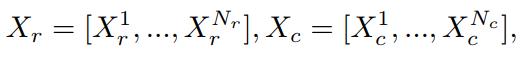
其中,包含个的交错行,包含个的交错列。
然后,分别在每个行Token组和列Token组中执行自注意力。使用3个可分离的卷积层、、生成Query、Key和Value。
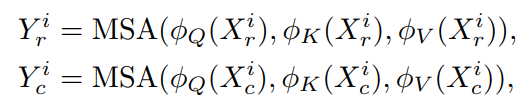
MSA表示多头自注意力。
最后,行方向和列方向的注意力输出沿着通道尺寸连接,得到最终的输出:
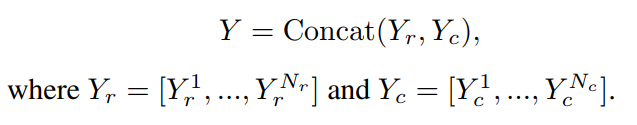
与PS-Attention在整个系统内的普通实现相比,这种并行机制具有较低的计算复杂度。此外,填充操作只需要确保能被整除,能被整除,而不是。因此,也有利于避免填充过多。
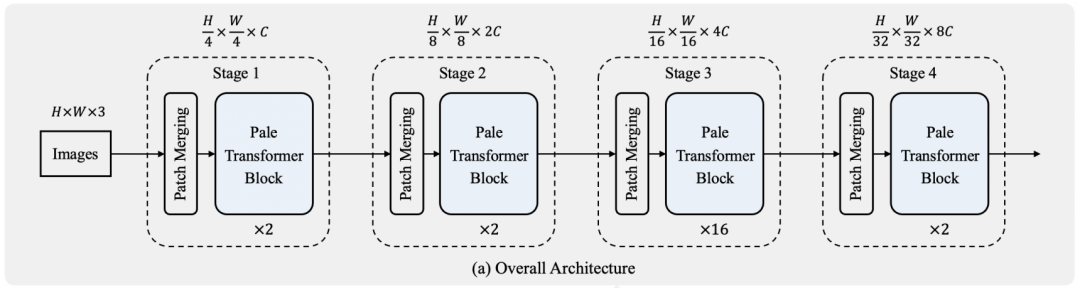
Pale Transformer Block
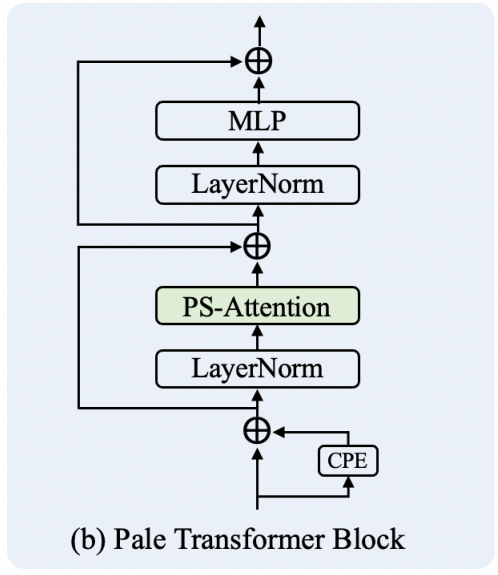
整体结构
![论文笔记——[CVPR2019]Noise2Void-Learning Denoising from Single Noisy Images](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420145844-150x89.png)
![论文笔记——[SIGGRAPH2023]Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://blog.liguanxin.cn/wp-content/uploads/2023/05/微信截图_20230529202716-150x53.png)

![论文笔记——[ICCV 2021]Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220725143207-150x86.png)