创新点:
①两个循环协作的网络,一个恢复图像,一个评估landmark
②注意力融合模块
解决的痛点:通过低分辨率图片 LR 或者粗超分辨率图片 SR 得到的人脸先验信息不一定准确
大部分方法使用人脸先验的方式为简单的 concatenate 操作,不能充分利用先验信息
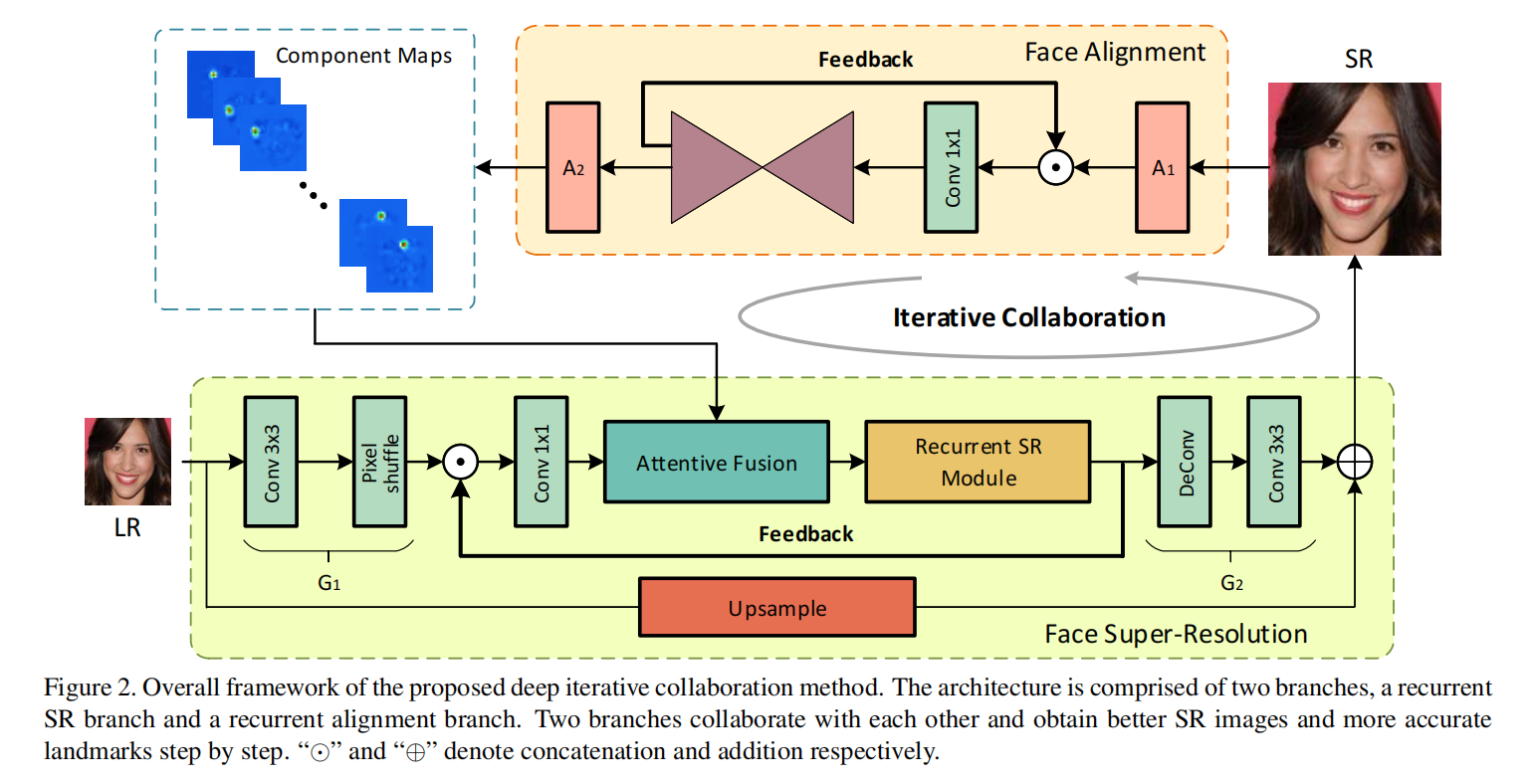
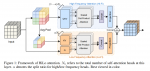
在此框架中,人脸恢复和关键点定位同时并递归执行。 如果输入人脸的质量更高,则可以通过准确的关键点获得更好的SR图像,因为可以更正确地估计关键点。 这两个过程可以互相促进,并逐步达到更好的性能。
其中循环SR分支G包括低分辨率特征提取器G1,递归块GR和高分辨率生成层G2。 GR包括一个注意融合模块和一个循环SR模块。 类似于SR分支,递归对齐分支包括一个预处理模块A1,一个递归沙漏模块AR和一个后处理模块A2。 对于第n步,其中n = 1,…,N,SR分支通过使用对齐结果和前一步n-1的反馈信息来恢复SR图像InSR。 此外,LR输入在每个步骤中也很重要。 因此,由G1提取的LR特征也被送到递归块中。 因此,可以通过以下方式来计算人脸SR过程:
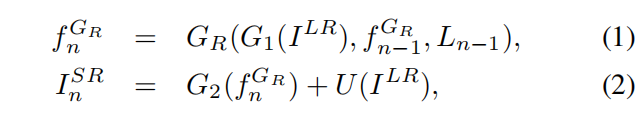
其中U表示上采样操作。 同样,人脸对齐分支将前一步中的循环特征和A1从SR图像InSR中提取的SR特征用作更准确地估计关键点的指导,如下所示:
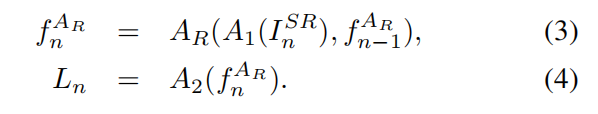
损失计算(L2范数):
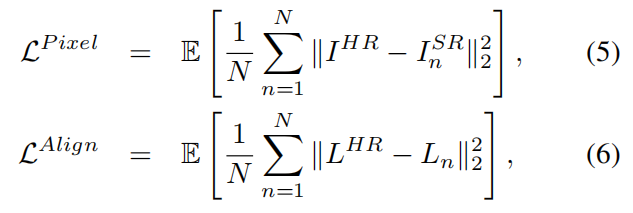
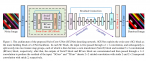
注意力融合模块
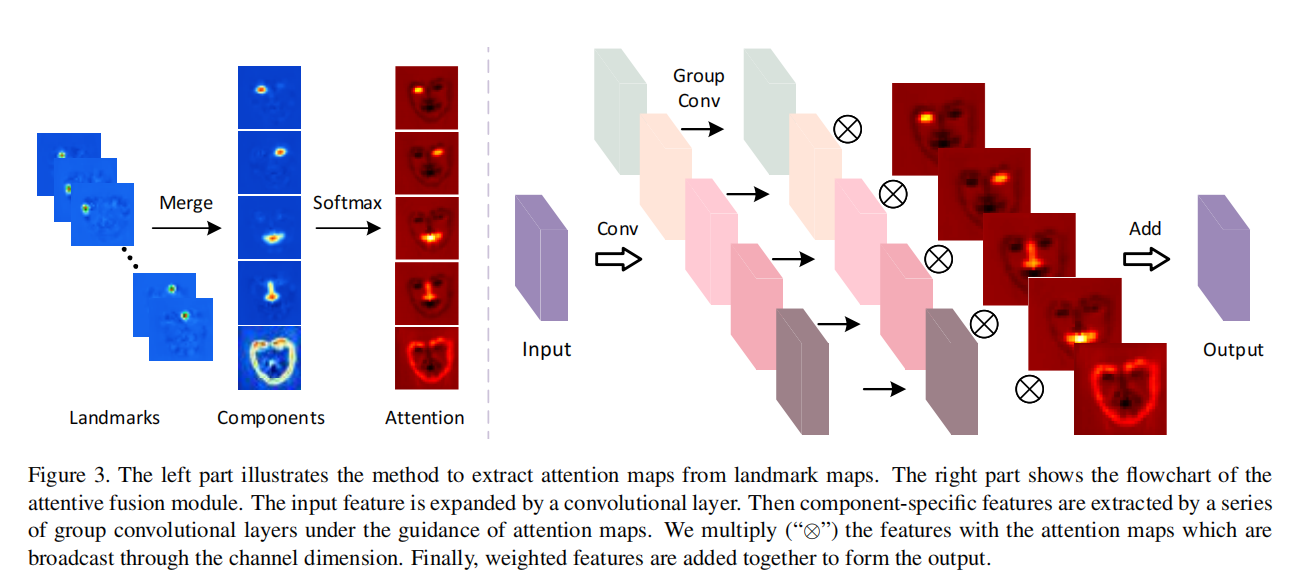
PixelShuffle(像素重组)的主要功能是将低分辨的特征图,通过卷积和多通道间的重组得到高分辨率的特征图。这一方法最初是为了解决图像超分辨率问题而提出的,这种称为Sub-Pixel Convolutional Neural Network的方法成为了上采样的有效手段。
代码
注意力融合模块(通过指定mark的编号来确定五官)
def merge_heatmap_5(heatmap_in, detach):
'''
merge 68 heatmap to 5
heatmap: B*N*32*32
'''
# landmark[36:42], landmark[42:48], landmark[27:36], landmark[48:68]
heatmap = heatmap_in.clone()
max_heat = heatmap.max(dim=2, keepdim=True)[0].max(dim=3, keepdim=True)[0]
max_heat = torch.max(max_heat, torch.ones_like(max_heat) * 0.05)
heatmap /= max_heat
if heatmap.size(1) == 5:
return heatmap.detach() if detach else heatmap
elif heatmap.size(1) == 68:
new_heatmap = torch.zeros_like(heatmap[:, :5])
new_heatmap[:, 0] = heatmap[:, 36:42].sum(1) # left eye
new_heatmap[:, 1] = heatmap[:, 42:48].sum(1) # right eye
new_heatmap[:, 2] = heatmap[:, 27:36].sum(1) # nose
new_heatmap[:, 3] = heatmap[:, 48:68].sum(1) # mouse
new_heatmap[:, 4] = heatmap[:, :27].sum(1) # face silhouette
return new_heatmap.detach() if detach else new_heatmap
elif heatmap.size(1) == 194: # Helen
new_heatmap = torch.zeros_like(heatmap[:, :5])
tmp_id = torch.cat((torch.arange(134, 153), torch.arange(174, 193)))
new_heatmap[:, 0] = heatmap[:, tmp_id].sum(1) # left eye
tmp_id = torch.cat((torch.arange(114, 133), torch.arange(154, 173)))
new_heatmap[:, 1] = heatmap[:, tmp_id].sum(1) # right eye
tmp_id = torch.arange(41, 57)
new_heatmap[:, 2] = heatmap[:, tmp_id].sum(1) # nose
tmp_id = torch.arange(58, 113)
new_heatmap[:, 3] = heatmap[:, tmp_id].sum(1) # mouse
tmp_id = torch.arange(0, 40)
new_heatmap[:, 4] = heatmap[:, tmp_id].sum(1) # face silhouette
return new_heatmap.detach() if detach else new_heatmap
else:
raise NotImplementedError('Fusion for face landmark number %d not implemented!' % heatmap.size(1))结构主体
class DIC(nn.Module):
def __init__(self, opt, device):
...
# LR feature extraction block
self.conv_in = ConvBlock(
in_channels,
4 * num_features,
kernel_size=3,
act_type=act_type,
norm_type=norm_type)
self.feat_in = nn.PixelShuffle(2)
...
self.out = DeconvBlock( # 反卷积层
num_features,
num_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
act_type='prelu',
norm_type=norm_type)
self.conv_out = ConvBlock( # 卷积
num_features,
out_channels,
kernel_size=3,
act_type=None,
norm_type=norm_type)
self.HG = FeedbackHourGlass(hg_num_feature, hg_num_keypoints)
def forward(self, x):
inter_res = nn.functional.interpolate(
x,
scale_factor=self.upscale_factor,
mode='bilinear',
align_corners=False)
batch_size = x.size(0)
x = self.conv_in(x) # 3*3卷积
x = self.feat_in(x) # pixelshuffle操作
sr_outs = []
heatmap_outs = []
hg_last_hidden = None
# initalize heatmap and FB feature with first coarse block
for step in range(self.num_steps):
if step == 0:
FB_out_first = self.first_block(x) # 第一个循环的block用LR的特征作为输入
h = torch.add(inter_res, self.conv_out(self.out(FB_out_first)))
heatmap, hg_last_hidden = self.HG(h, hg_last_hidden)
self.block.last_hidden = FB_out_first
assert self.block.should_reset == False
else:
FB_out = self.block(x, merge_heatmap_5(heatmap, self.detach_attention))
h = torch.add(inter_res, self.conv_out(self.out(FB_out)))
heatmap, hg_last_hidden = self.HG(h, hg_last_hidden)
sr_outs.append(h)
heatmap_outs.append(heatmap)
return sr_outs, heatmap_outs # return output of every timesteps疑问
为什么人脸超分的文章会补充一个GAN网络?
答:因为直接用网络生成的人脸图像指标好。而用gan生成的图像观感好,但是指标略低。
![论文笔记——[CVPR2019]Noise2Void-Learning Denoising from Single Noisy Images](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420145844-150x89.png)
![论文笔记——[CVPR 2022 Oral]MetaFormer is Actually What You Need for Vision](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220701190629-150x111.png)
![论文笔记——[CVPR workshop 2022]Transformer for Single Image Super-Resolution](https://blog.liguanxin.cn/wp-content/uploads/2022/11/微信截图_20221106143431-150x47.png)