StyleGAN
StyleGAN是由Nvidia研究人员于2018年12月推出的生成对抗网络,并于2019年2月可用。
StyleGAN依赖于Nvidia的CUDA软件,GPU和Google的TensorFlow。
StyleGAN的第二个版本(称为StyleGAN2)于2020年2月5日发布。它消除了一些特征性伪影并提高了图像质量。
StyleGAN是一个生成人脸的GAN网络。整个网络结构还是保持了PG-GAN的结构,从低分辨率到高分辨率渐变的训练方法。
基于风格迁移的generator
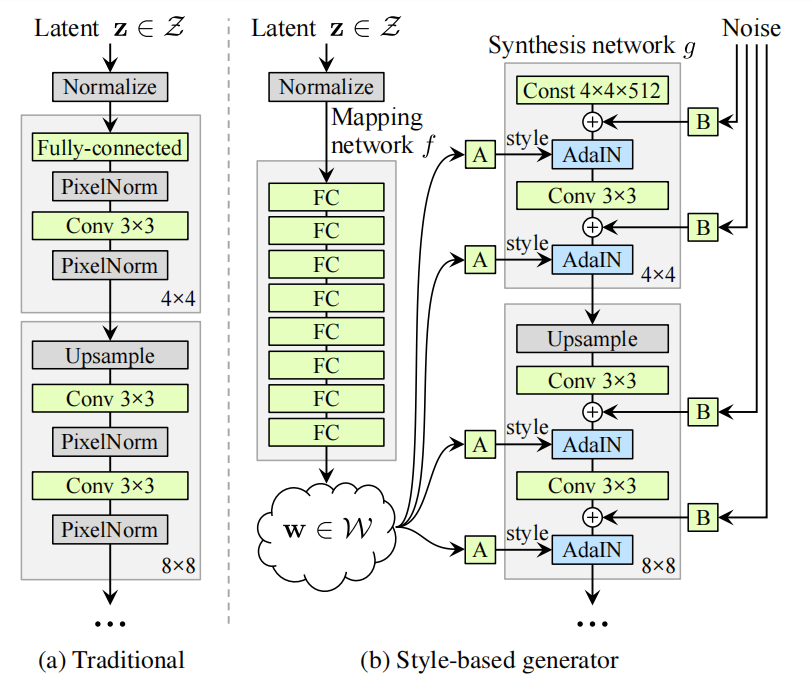
传统的生成器把潜在特征编码(随机变量或隐藏变量)直接喂给输入层。
本文方法是把潜在特征编码先经过一个Mapping网络投射到W空间,然后控制生成器通过在每个卷积层上的自适应实例归一化(AdaIN)。
Z 和 W 的维度都是512维。
每次卷积后加入高斯噪声,“A”代表可学习的仿射变换,“B”代表可学习的通道比例因子。A 是由 w 转换得到的仿射变换,用于控制生成图像的风格,B 是转换后的随机噪声,用于丰富生成图像的细节,即每个卷积层都能根据输入的A来调整"style"。Mapping网络f由8层FC层(全连接层)构成,而综合网络g由18层构成每个分辨率各两层(4^2-1024^2)。输入的最后一层是一个1*1卷积转换为RGB。
仿射变换,又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。
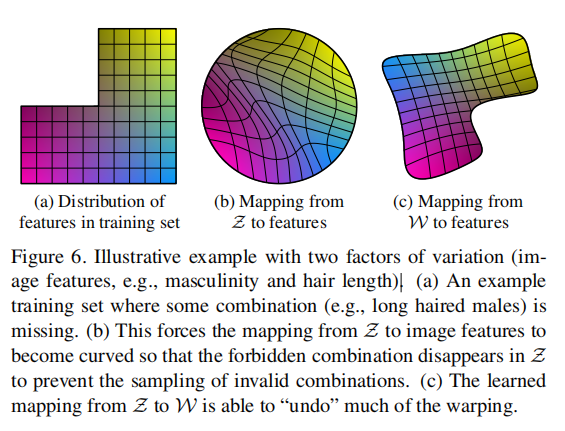
为什么要把z投射到w?(什么是解纠缠语义?)
答:如下图,在数据集中,假设有两个属性:男性化和长头发。而数据集中通常缺少男性长发的样本。(a)表示数据集中的实际分布。但是如果假设分布均匀的话,z空间分布会当作一个满足高斯分布的圆形,如(b)。把z投射到w就是为了让这个圆形还原回实际的分布情况也就是(c)。
Style mixing
下图中第一行是 source B, 第一列是source A,source A和 source B的每张图片由各自相应的latent code生成,剩余的图片是对 source A和 souce B风格的组合。Style mixing的本意是去找到控制不同style的latent code的区域位置,具体做法是将两个不同的latent code z1和z2输入到mappint network中,分别得到w1和w2,分别代表两种不同的style,然后在Synthesis network中随机选一个中间的交叉点,交叉点之前的部分使用w1,交叉点之后的部分使用w2,生成的图像应该同时具有source A和source B的特征,称为style mixing。
根据交叉点选取位置的不同,style组合的结果也不同,如下图:


Truncation Trick
从数据分布来说,低概率密度的数据在网络中的表达能力很弱,直观理解就是,低概率密度的数据出现次数少,能影响网络梯度的机会也少,但并不代表低概率密度的数据不重要。可以提高数据分布的整体密度,把分布稀疏的数据点都聚拢到一起,类似于PCA,做法很简单,首先找到数据中的一个平均点,然后计算其他所有点到这个平均点的距离,对每个距离按照统一标准进行压缩,这样就能将数据点都聚拢了,但是又不会改变点与点之间的距离关系。

StyleGAN2
StyleGAN2的出现是因为StyleGAN存在瑕疵,少量生成的图片有明显的水珠。

导致水珠的原因作者认为是Adain操作,Adain对每个feature map进行归一化,因此有可能会破坏掉feature之间的信息。改为如下结构之后,水珠就消失了。
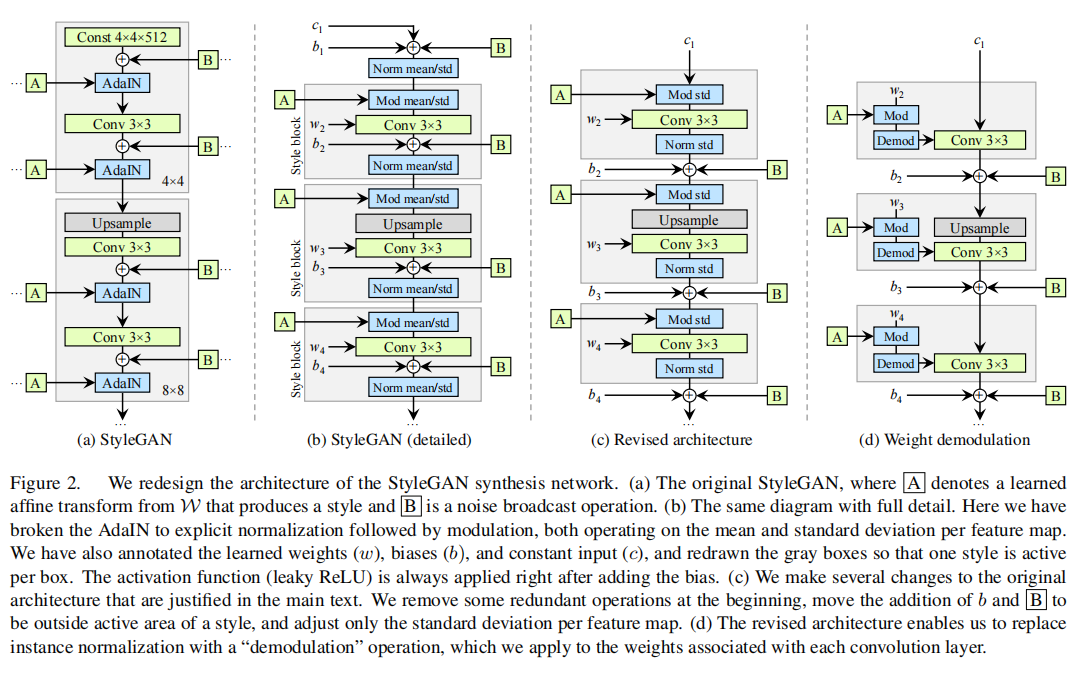
mod和demod

![论文笔记——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420151210-150x88.png)
![论文笔记——[CVPR 2020]Learning Spatial Attention for Face Super-Resolution](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220712212242-150x38.png)

![论文笔记——[AAAI 2022]Less is More: Pay Less Attention in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220720201734-150x70.png)
![论文笔记——[ICCV 2021]Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220725143207-150x86.png)
评论列表