创新点:
①协同尺度的卷积注意力机制(并行、串行)
②通过卷积实现embedding的相对位置(减少计算量)
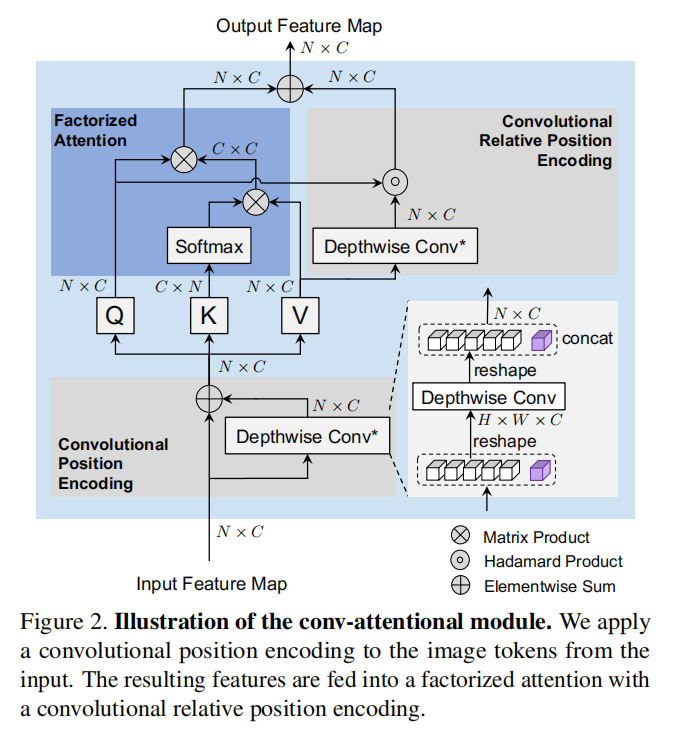
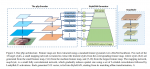
基于卷积的的注意力模块总体结构
分析自注意力机制
在自注意力计算中
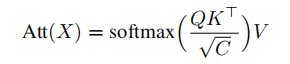
softmax逻辑和注意图QK^T导致了O(N^2)的空间复杂度和O(N^2C)的时间复杂度,于是作者提出了一种分解方法来减少这些复杂度。
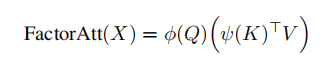
其中\mathcal{\phi}(\cdot), \mathcal{\psi}(\cdot) : \mathbb{R}^{N \times C} \rightarrow \mathbb{R}^{N \times C^{\prime}},空间复杂度减少至O(NC^{\prime}+NC+CC^{\prime}),时间复杂度O(NCC^{\prime})
更进一步采用以下公式
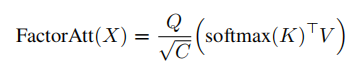
空间复杂度O(NC+C^2),时间复杂度O(NCC^2)
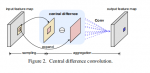
基于卷积的相对位置编码

其中P为DW卷积的权重,首先对V进行DW卷积,再与Q做逐元素乘,得到相对位置图\hat{EV},再与一个0向量concat,以对齐cls token。
基于卷积的位置编码
相对位置编码模型是Q和V之间基于位置的局部关系,而位置编码是一个全局的位置编码。本文在注意力机制前增加了一个DW卷积来得到绝对位置编码。
对于全局位置编码采用kernel size为3,对于不同头的相对位置编码分别采用3、5、7的kernel size。
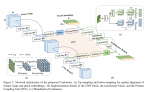
总体结构
协同尺度的Transformer
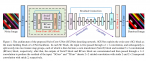
串行块
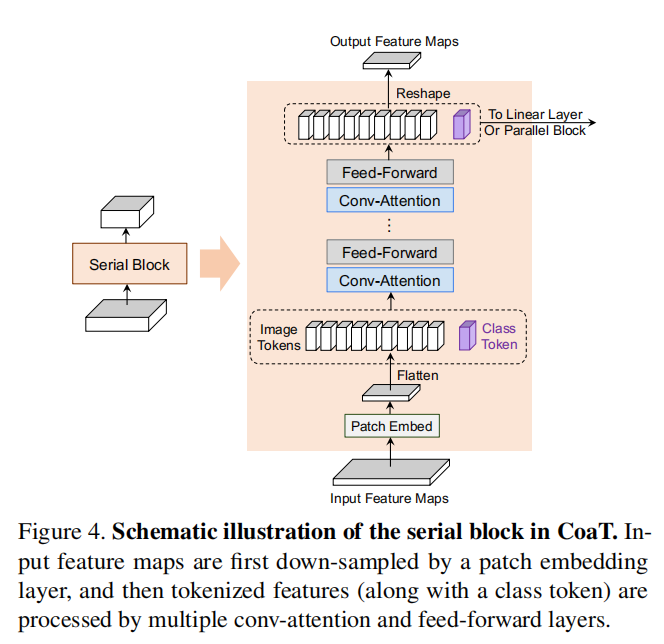
首先通过Patch Embed对图像进行下采样,然后flatten成一系列的特征token并增加一个用于图像分类的cls token。然后执行基于卷积的自注意力模块。最后把cls token分离,把特征token还原为2D特征图。
并行块
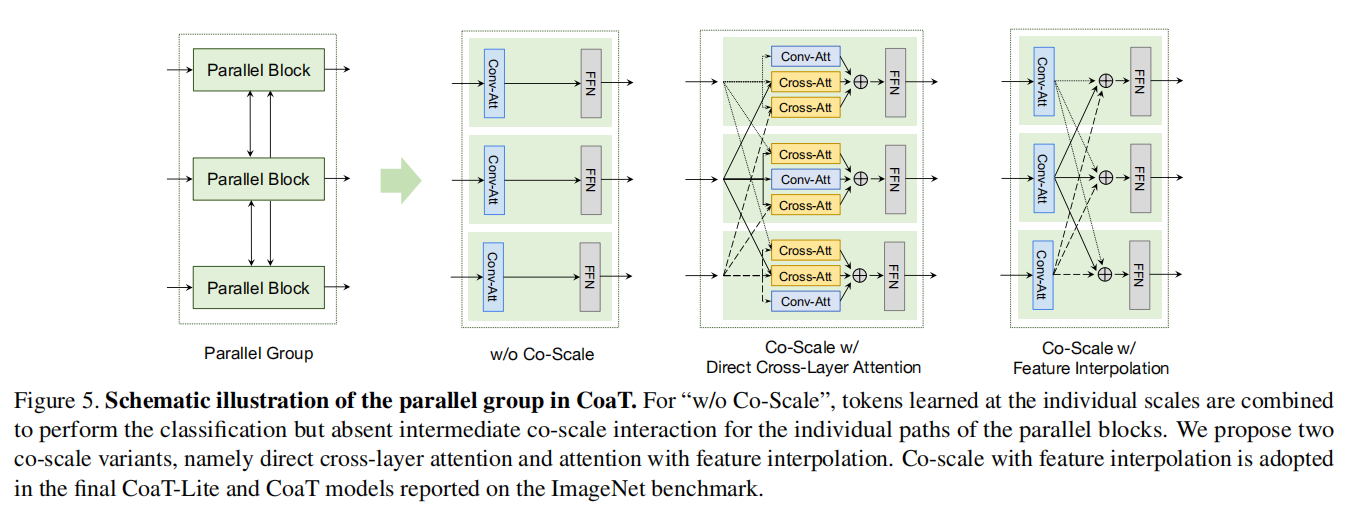
让不同块并行的方式有两种:
- 直接跨层注意力:对于不同层的块,让K和V下采样或上采样来匹配其他尺度的分辨率来执行交叉注意力。
- 特征插值注意力:不同尺度的特征独立计算自注意力,计算完之后通过双线性插值来匹配其他尺度。
本文最终采用特征插值来让不同层的特征交互。
总体结构
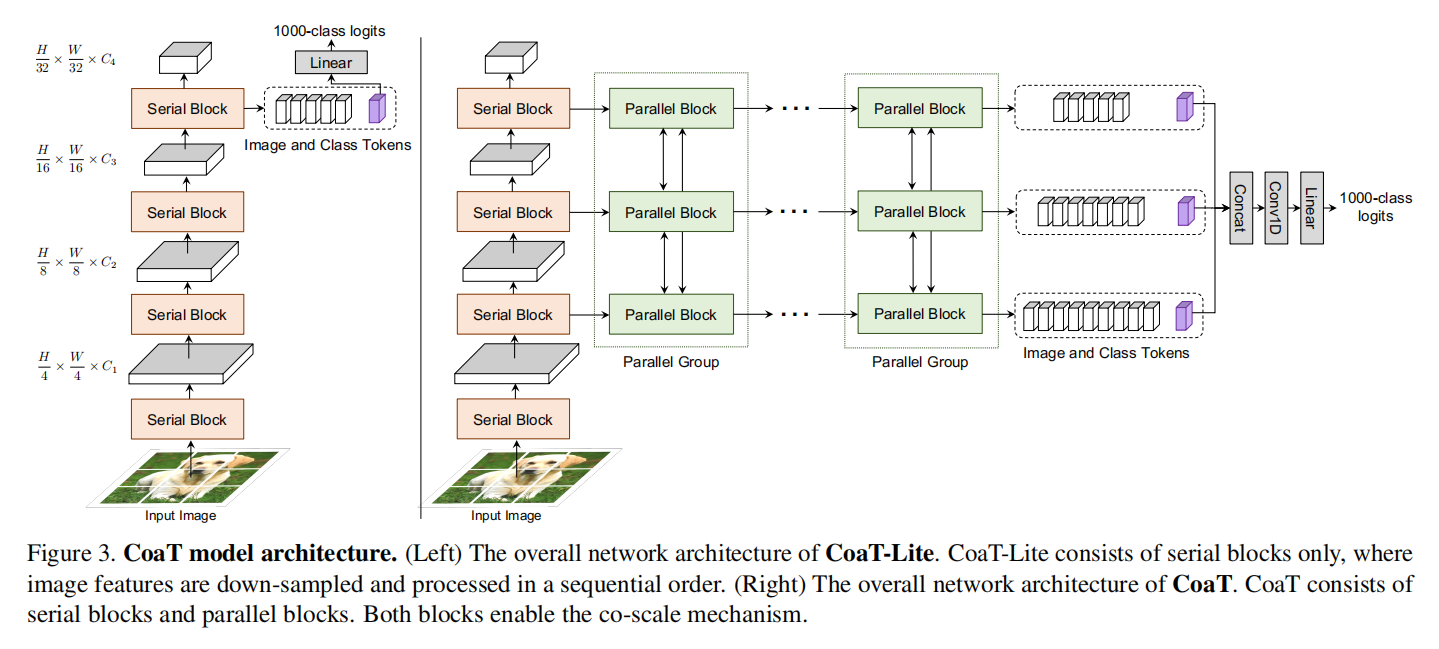
CoaT-Lite: 采用金字塔结构,仅由串行块构成,通过最后获得的CLS token来进行分类任务。
CoaT: 由串行块和并行块构成,从三个尺度concat cls token。
实验结果
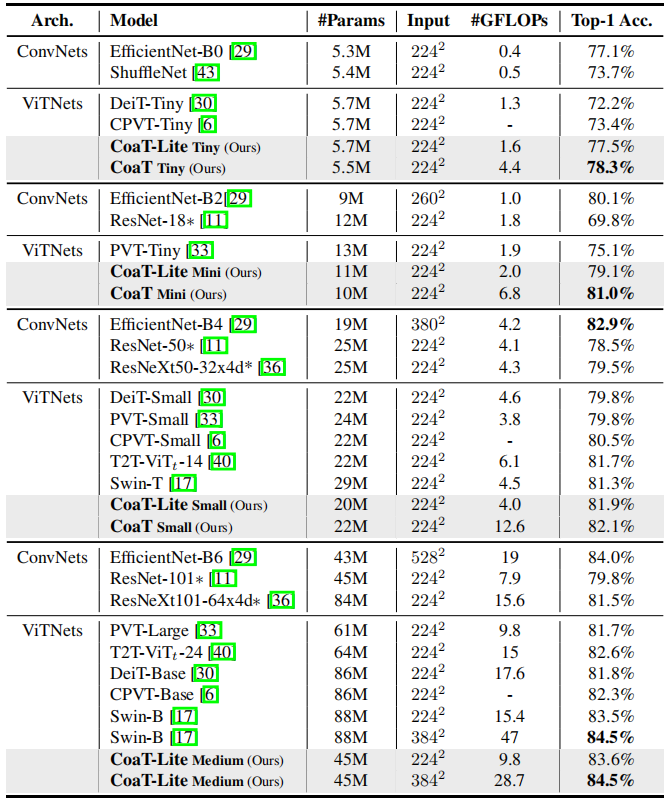
在参数量更少的情况下与Swin持平
同等参数量的情况下准确度更高
![论文笔记——[CVPR2022]A ConvNet for the 2020s](https://blog.liguanxin.cn/wp-content/uploads/2022/06/微信截图_20220630121941-150x101.png)
![论文笔记——[AAAI 2022]Less is More: Pay Less Attention in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220720201734-150x70.png)