基础知识:基于3DMM的三维人脸重建技术总结
(潜码和噪声的概念见StyleGAN)
(GAN逆转的文章见In-Domain GAN Inversion for Real Image Editing)
大部分的3d人脸重建因为隐私问题不提供数据集和模型
创新点:
①条件神经渲染器
②神经网络采用人脸法线贴图和潜码作为输入来产生真实图像,能有效抑制训练和优化中的域移位(domain-shift noise)噪声
③提出一种预测3D人脸参数的方法,首先通过GAN反转来获得初始参数,然后利用基于梯度的优化器进行微调
之前方法存在的问题:普通的神经网络模型,只通过反向传播来训练,而使用简单的渲染图像法决定了重建效果的上限,简化了现实世界的照明、反射等现实机制,无法产生真实的图像。
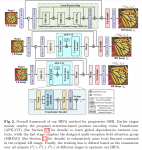
方法
训练方法:给定一个图像,通过GAR逆转网络生成潜码和噪声,通过反向传播微调所有参数和潜码。
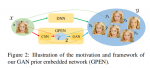
Generative Adversarial Renderer(GAR)

左侧是本文提出的生成对抗渲染器,接受一个法线贴图n和潜码z作为输入,并输出渲染好的图。
类似StyleGAN v2,渲染器由一系列的Render Block构成:
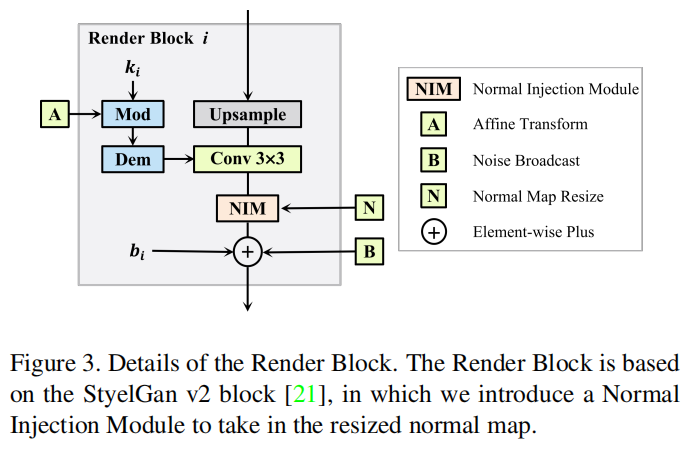
对应于一定的分辨率,Render Block包含一个style-varying卷积。输入潜码z经过8层MLP转换到了参数w后,w通过对卷积核进行仿射变换(按理说仿射变换是对数据进行缩放和平移操作的,style GAN就是这样,但是style GAN v2将平移给去掉了,只剩下缩放),其实就相当于变相地对特征图(每一层渲染块的输出,最开始是C1)进行仿射变换了,而这种仿射变换,在style GAN v2里面正是影响图像风格的关键因素。
卷积核参数k进行仿射变换的过程:
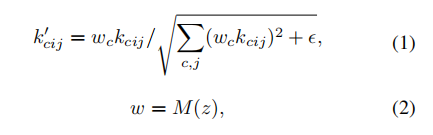
分子是图中的Mod模块(调制,modulation),分母是图中的Dem模块(解调制,demodulation),可以理解为根据方差进行数据的归一化,其中的ϵ是为了防止除以0。
之后就是卷积操作了:
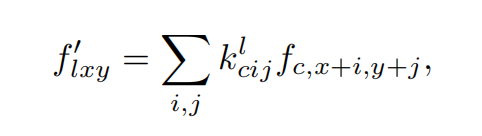
通过NIM(法线注入)模块,把法线贴图作用与网络中:
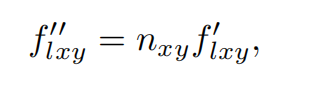
f是三维向量,n_{xy}代表法线贴图(x, y)处的值,法线贴图的RGB通道就相当于该点法线的x,y,z值了,也是个三维向量,对应相乘,就完成所谓的法线注入了。
最后加入噪声B,因为潜在代码z的小维数不能完全表达一个人脸图像的所有细节。因此,需要额外的噪声来正确地建模额外的信息。
卷积后的特征图由法线贴图N调制。于是可以生成不同形状α、表情β和姿势θ参数构成的3DMM人脸模型。
损失函数
法线一致性损失:
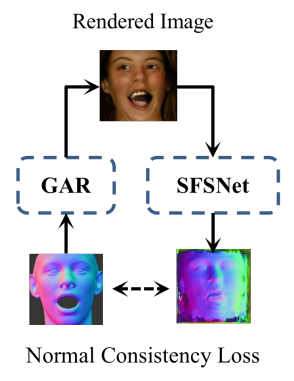
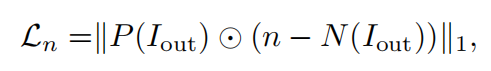
P是为了遮挡非脸部区域,n是原本输入渲染器的法线贴图,N是采用SFSNet网络预测渲染图像的法线贴图,得到该损失。
面部关键点一致性损失:
为了让潜码z不控制形状,而完全让法线贴图控制形状,于是考虑一种损失函数让二者解耦合:
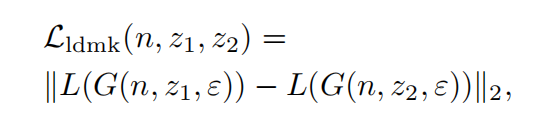
原理是让渲染器渲染两个不同的潜码z_1,z_2,两个用同一个法线贴图n,这样出来的形状应该是相同的,函数L是人脸关键点检测,用人脸关键点的距离来代替形状相似性的判断。
身份损失:
在法线贴图不同的时候,渲染出的人物可能是同一个人,可能是不同的人,具体是由其背后的3DMM系数与姿态系数(相机参数)控制的,于是为了让渲染器能够捕捉到法线贴图所蕴含的身份信息,提出了如下损失函数:
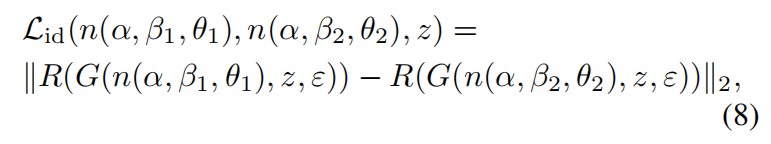
为了保证相同的形状α与相同的z的前提下,对于不同的表情与拍摄角度,渲染器渲染出的是同一个人,其中的R是一个人脸识别网络
总损失函数:
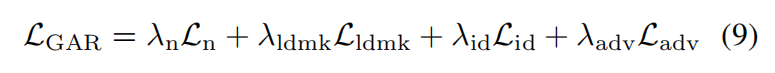
优化
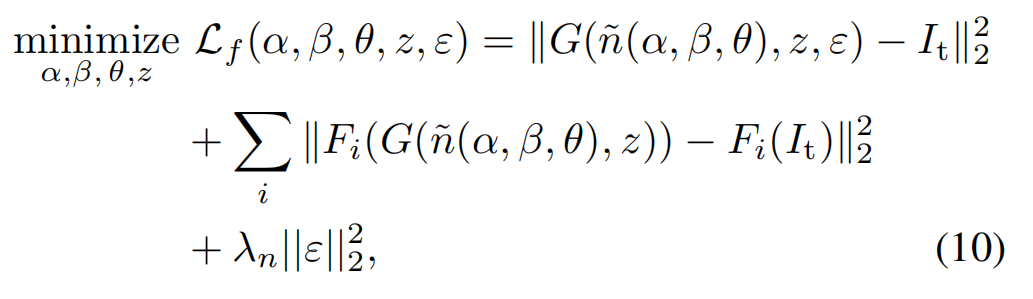
其中G表示固定的对抗生成渲染器,\hat{n}代表通过几何系数 (α, β, θ)构建的法线贴图,F_i是第i层特征图经过预训练的VGG网络构建的感知损失,\lambda_n对随机噪声的正则化项进行加权。
逆转渲染器来获得初始参数
参数的初始化分为两部分,一部分是初始化z,通过设计了与渲染器对称的一种反转网络结构,用统计平均值和方差来估计z,如下式子所示:
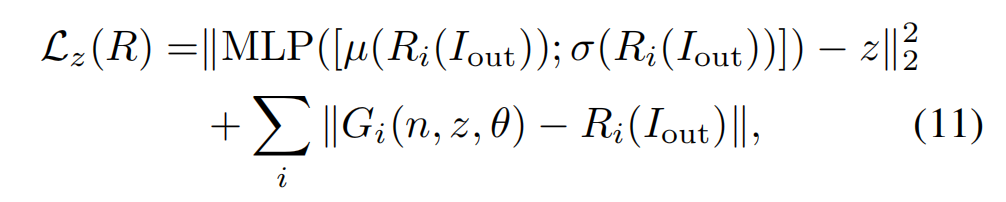
其中为了估计初始输入,I_out就给换成输入要准备重建的图像了,根据估计的初始输入再正向渲染一波,渲染图应该就和输入图像差个不离了。
另一部分参数的初始化就是3DMM系数了,直接用简单粗暴的传统方法:
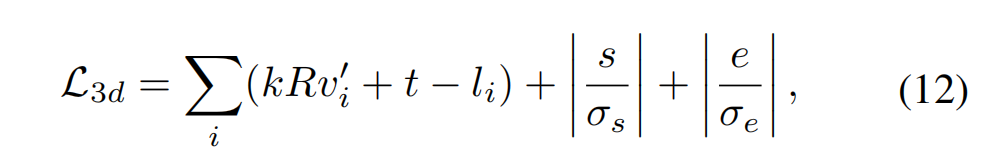

![论文笔记——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420151210-150x88.png)
![论文笔记——[CVPR 2022 Oral]MetaFormer is Actually What You Need for Vision](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220701190629-150x111.png)
![论文笔记——[CVPR workshop 2022]Transformer for Single Image Super-Resolution](https://blog.liguanxin.cn/wp-content/uploads/2022/11/微信截图_20221106143431-150x47.png)
![论文笔记——[ICML2018]Noise2Noise: Learning Image Restoration without Clean Data](https://blog.liguanxin.cn/wp-content/uploads/2022/04/20180715170032-150x81.png)