创新点:
①以数据依赖的方式在自注意力计算中选择K和V对。
②通过一个网络学习offset坐标,采用双线性插值计算位置。
与其他网络的对比(Attention模块)

(a) 对所有patch采用相同的自注意力(计算量和内存占用巨大)
(b) 对划分的窗口采用自注意力(稀疏注意力,对更远的数据不可知,注意力窗口与数据无关)
(c) 可变形卷积,寻找需要卷积的区域(卷积区域不能扩大)
(d) 本文的方法,自己学习对应的注意力区域
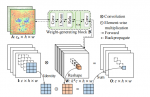
可变形卷积(DCN):
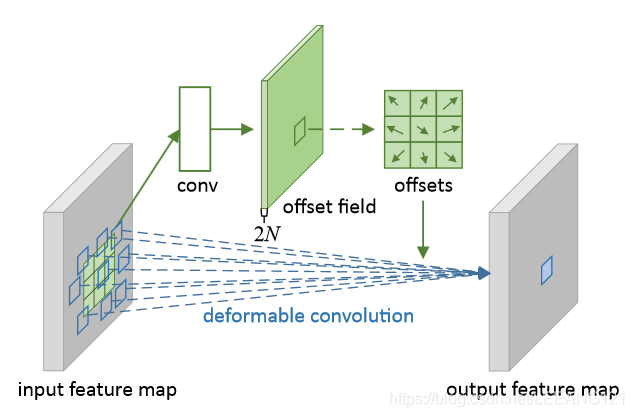
假设卷积区域为3×3,先对整体特征图做3×3conv得到大小为h×w×(2×k×k)的位置偏移矩阵,任意一点可以获得2×k×k的位置偏移信息(浮点数变量通过线性插值法算出具体的值),对偏移后的值做普通卷积操作即可。
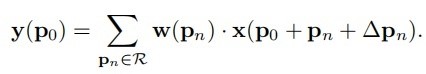
Attention结构
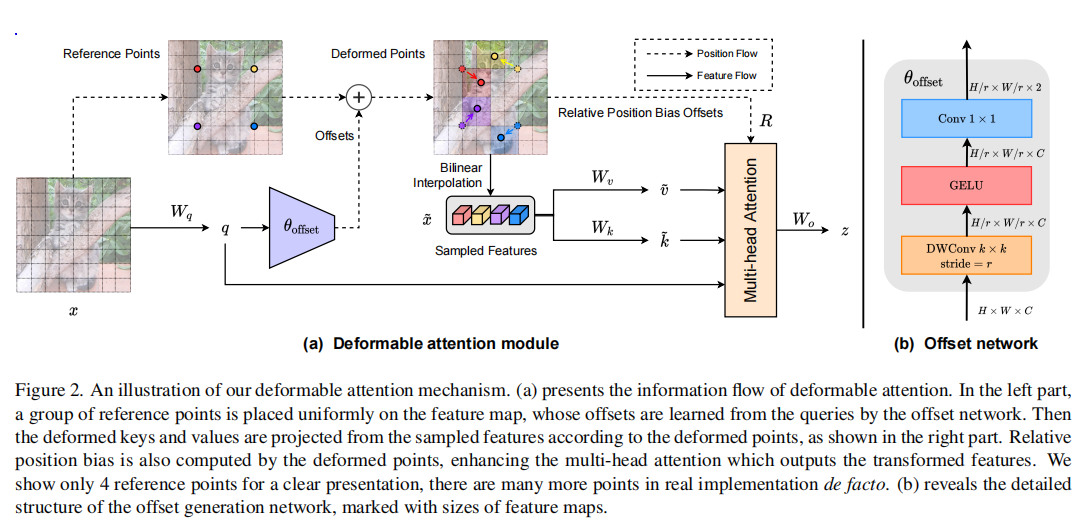
(a) 均匀放置参考点,数量为group,通过一个Offset网络学习参考点的偏移,偏移后的坐标有两个作用:
- 找到最近的四个坐标,双线性插值计算得到patch
- 计算相对位置偏置作为B
(b) Offset计算网络,由一个5×5 depthwise卷积(stride=r)、一个GELU激活层和一个1×1卷积(out_channel=2, 无bias)构成。
双线性插值
双线性插值后的x通过以下公式得到:
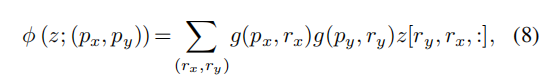
其中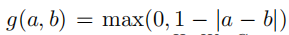 是为了找到离偏移后的点距离在一个单位以内,大于一个单位的计算会变成0,而rx和ry是所有的坐标对应的值。
是为了找到离偏移后的点距离在一个单位以内,大于一个单位的计算会变成0,而rx和ry是所有的坐标对应的值。
双线性插值可以用下图理解:

相对位置偏置
由于特征图是全尺寸H×W的,相对位置偏置矩阵也应该是全尺寸的\hat{B} \in \mathbb{R}^{{2H-1} \times {2W-1}}
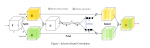
网络总体结构
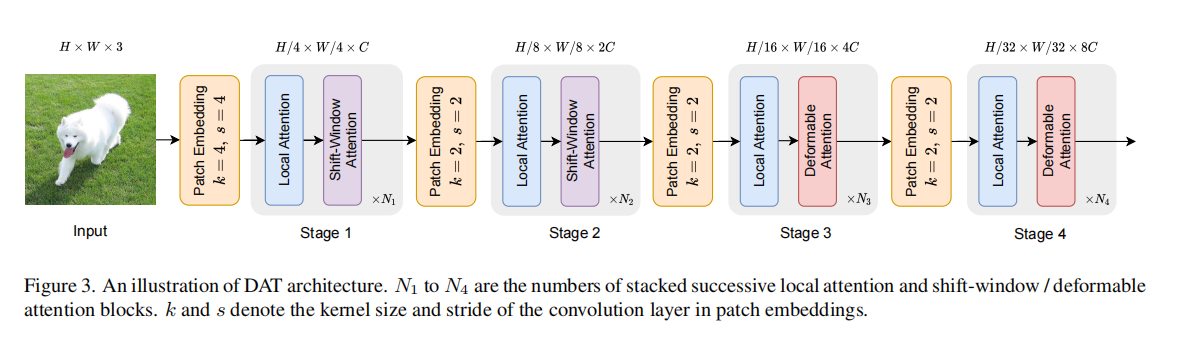
作者通过实验证明,前两个stage用swin,后两个stage用dat得到的结果最好。
各stage的参数:

CODE
DAttention的代码
def forward(self, x):
B, C, H, W = x.size()
dtype, device = x.dtype, x.device
# 通过1*1卷积投影得到q
q = self.proj_q(x)
# 把q分为g个组
q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
# 经过offset网络
offset = self.conv_offset(q_off) # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
# 计算特征图大小
n_sample = Hk * Wk
# 计算偏移量,先把偏移量通过tanh把范围归到-1~1,再除以对应的高或者宽,乘以最大偏移量offset_range_factor
if self.offset_range_factor > 0:
offset_range = torch.tensor([1.0 / Hk, 1.0 / Wk], device=device).reshape(1, 2, 1, 1)
offset = offset.tanh().mul(offset_range).mul(self.offset_range_factor)
offset = einops.rearrange(offset, 'b p h w -> b h w p')
# 得到等距位置信息矩阵
reference = self._get_ref_points(Hk, Wk, B, dtype, device)
if self.no_off:
offset = offset.fill(0.0)
if self.offset_range_factor >= 0:
# 位置信息矩阵加上范围为-offset_range_factor~+offset_range_factor的偏移
pos = offset + reference
else:
pos = (offset + reference).tanh()
# grid_sample提供一个input以及一个网格,然后根据grid中每个位置提供的坐标信息(input中pixel的坐标),
# 将input中对应位置的像素值填充到grid指定的位置,得到最终的输出。
# 位置非整数则采用线性插值法
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
x_sampled = x_sampled.reshape(B, C, 1, n_sample)
# q之前已经得到,通过采样后的x_sampled计算k和v
q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)
k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
# q乘k
attn = torch.einsum('b c m, b c n -> b m n', q, k) # B * h, HW, Ns
# 乘以缩放倍数
attn = attn.mul(self.scale)
# 使用偏置
if self.use_pe:
if self.dwc_pe:
# 只在最后加上偏置
residual_lepe = self.rpe_table(q.reshape(B, C, H, W)).reshape(B * self.n_heads, self.n_head_channels, H * W)
elif self.fixed_pe:
# 固定偏置(学习所有可能的q和k的固定位置)
rpe_table = self.rpe_table
attn_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
attn = attn + attn_bias.reshape(B * self.n_heads, H * W, self.n_sample)
else:
# 相对偏置(学习所有可能的q和k的相对位置)
rpe_table = self.rpe_table
rpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
q_grid = self._get_ref_points(H, W, B, dtype, device)
displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups, n_sample, 2).unsqueeze(1)).mul(0.5)
attn_bias = F.grid_sample(
input=rpe_bias.reshape(B * self.n_groups, self.n_group_heads, 2 * H - 1, 2 * W - 1),
grid=displacement[..., (1, 0)],
mode='bilinear', align_corners=True
) # B * g, h_g, HW, Ns
attn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)
# qk之后加上位置偏置
attn = attn + attn_bias
attn = F.softmax(attn, dim=2)
attn = self.attn_drop(attn)
# qk之后经过softmax再乘v
out = torch.einsum('b m n, b c n -> b c m', attn, v)
if self.use_pe and self.dwc_pe:
out = out + residual_lepe
out = out.reshape(B, C, H, W)
# 再过一个1*1卷积
y = self.proj_drop(self.proj_out(out))
return y, pos.reshape(B, self.n_groups, Hk, Wk, 2), reference.reshape(B, self.n_groups, Hk, Wk, 2)MLP层
class TransformerMLPWithConv(nn.Module):
def __init__(self, channels, expansion, drop):
super().__init__()
self.dim1 = channels
self.dim2 = channels * expansion
self.linear1 = nn.Conv2d(self.dim1, self.dim2, 1, 1, 0)
self.drop1 = nn.Dropout(drop, inplace=True)
self.act = nn.GELU()
self.linear2 = nn.Conv2d(self.dim2, self.dim1, 1, 1, 0)
self.drop2 = nn.Dropout(drop, inplace=True)
self.dwc = nn.Conv2d(self.dim2, self.dim2, 3, 1, 1, groups=self.dim2)
def forward(self, x):
x = self.drop1(self.act(self.dwc(self.linear1(x))))
x = self.drop2(self.linear2(x))
return x其中默认drop都是0
![论文笔记——[ICCV 2021]Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220725143207-150x86.png)

![论文笔记——[CVPR 2020]Learning Spatial Attention for Face Super-Resolution](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220712212242-150x38.png)
![论文笔记——[NeurIPS 2021]Focal Self-attention for Local-Global Interactions in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220701221616-150x56.png)
请问有人用DAT的代码跑实验吗?我跑出的结果不理想
我没有试过,可变形卷积本身就挺难训的,或许跟你跑的任务有关?