(CVPR2022的去噪论文)
创新点:
①本文提出Swin-Conv模块,将DRUNet和SwinIR的结合起来,并插入到UNet架构中,还设计了一个实用的噪声退化模型,最终在盲图像去噪上表现SOTA。
②设计了一个实用的噪声退化模型,该模型考虑了不同类型的噪声(包括高斯噪声、泊松噪声、散斑噪声、JPEG压缩噪声和处理过的摄像机传感器噪声)和调整大小,并涉及到随机洗牌策略和双退化策略。
研究方向:
- 第一个是在n是加性高斯白噪声(AWGN)的假设下提高性能。
- 第二种方法主要集中在训练数据或噪声建模上。
优化问题

通常盲去噪是为了解决以下双级优化问题
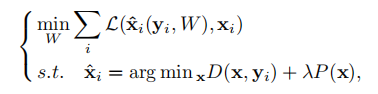
其中W代表网络要学习的参数,{y_i, x_i}代表噪声-干净图像对,L()是损失函数,λ是先验项权重。
网络结构Swin-Conv-UNet
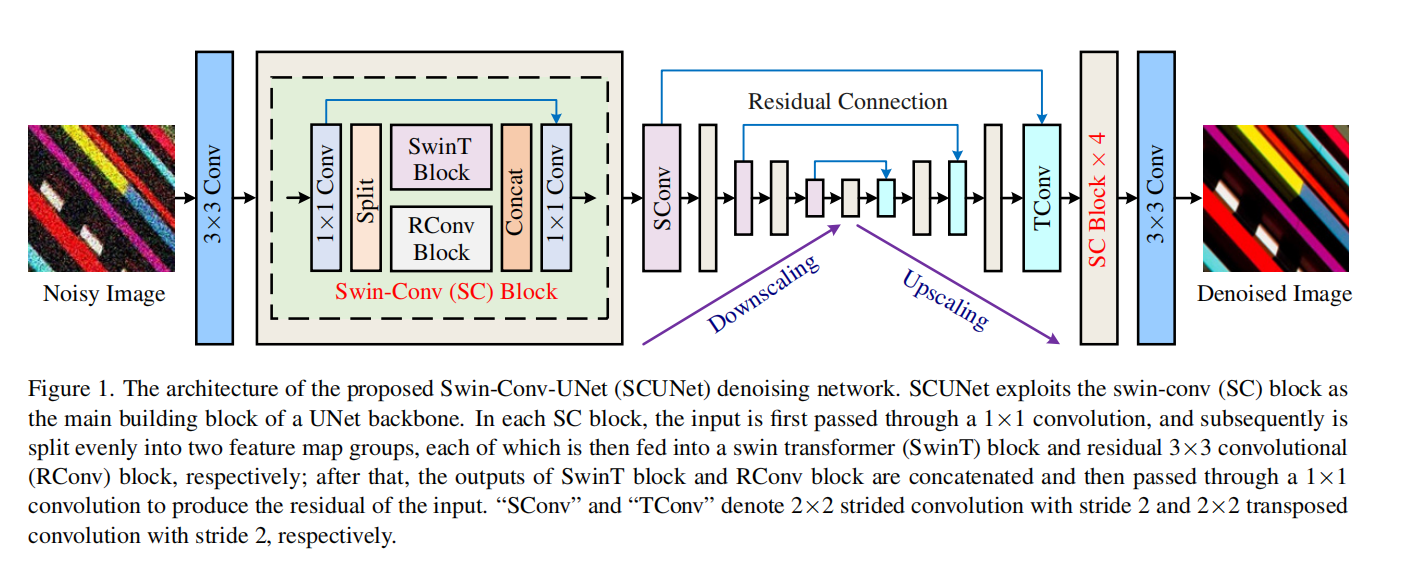
图中灰色框是SC Block,通过一个1*1卷积,然后均匀split成两个分支(维度平分),进入SwinT Block和RConv Block(残差卷积块—>3*3,ReLU,3*3),然后concat进入1*1卷积。
粉色框是SConv代表2*2步长为2的卷积。
蓝色框是TCconv代表2*2步长为2的反卷积。
从第一尺度到第四尺度,每一层的通道数分别为64、128、256和512。
SCUNet在缩小和升级的每个尺度上都采用了4个SC块,而不是4个残差卷积块。
CODE
整体结构是一个SCUNet
class SCUNet(nn.Module):
def __init__(self, in_nc=3, config=[2,2,2,2,2,2,2], dim=64, drop_path_rate=0.0, input_resolution=256):
super(SCUNet, self).__init__()
self.config = config
self.dim = dim
self.head_dim = 32
self.window_size = 8
# drop path rate for each layer
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(config))]
self.m_head = [nn.Conv2d(in_nc, dim, 3, 1, 1, bias=False)]
begin = 0
self.m_down1 = [ConvTransBlock(dim//2, dim//2, self.head_dim, self.window_size, dpr[i+begin], 'W' if not i%2 else 'SW', input_resolution)
for i in range(config[0])] + \
[nn.Conv2d(dim, 2*dim, 2, 2, 0, bias=False)]
...
def forward(self, x0):
# 图片高宽不足64补全到64
h, w = x0.size()[-2:]
paddingBottom = int(np.ceil(h/64)*64-h)
paddingRight = int(np.ceil(w/64)*64-w)
x0 = nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x0)
# 第一个3*3卷积
x1 = self.m_head(x0) # 64
# 两个SC Block(一个正常窗口,一个滑动窗口)和一个2*2下采样卷积
x2 = self.m_down1(x1) # 128
# 两个SC Block和一个2*2下采样卷积
x3 = self.m_down2(x2) # 256
# 两个SC Block和一个2*2下采样卷积
x4 = self.m_down3(x3) # 512
# U型结构底层也是两个SC Block
x = self.m_body(x4) # 512
# 经过一个2*2反卷积然后是两个SC Block,最后跟x4做残差
x = self.m_up3(x+x4) # 256
# 经过一个2*2反卷积然后是两个SC Block,最后跟x3做残差
x = self.m_up2(x+x3) # 128
# 经过一个2*2反卷积然后是两个SC Block,最后跟x2做残差
x = self.m_up1(x+x2) # 64
# 最后来一个3*3卷积收尾
x = self.m_tail(x+x1)
x = x[..., :h, :w]
return xSC Block:
class ConvTransBlock(nn.Module):
def __init__(self, conv_dim, trans_dim, head_dim, window_size, drop_path, type='W', input_resolution=None):
""" SwinTransformer and Conv Block
"""
super(ConvTransBlock, self).__init__()
...
self.trans_block = Block(self.trans_dim, self.trans_dim, self.head_dim, self.window_size, self.drop_path, self.type, self.input_resolution)
...
self.conv_block = nn.Sequential(
nn.Conv2d(self.conv_dim, self.conv_dim, 3, 1, 1, bias=False),
nn.ReLU(True),
nn.Conv2d(self.conv_dim, self.conv_dim, 3, 1, 1, bias=False)
)
def forward(self, x):
# 经过1*1卷积之后split成两份
conv_x, trans_x = torch.split(self.conv1_1(x), (self.conv_dim, self.trans_dim), dim=1)
# 残差卷积块
conv_x = self.conv_block(conv_x) + conv_x
# 窗口自注意力
trans_x = Rearrange('b c h w -> b h w c')(trans_x)
trans_x = self.trans_block(trans_x)
trans_x = Rearrange('b h w c -> b c h w')(trans_x)
# 结果concat一起
res = self.conv1_2(torch.cat((conv_x, trans_x), dim=1))
x = x + res
return x![论文笔记——[CVPR 2022 Oral]Restormer: Efficient Transformer for High-Resolution Image Restoration](https://blog.liguanxin.cn/wp-content/uploads/2022/11/网络-150x72.png)
![论文笔记——[SIGGRAPH2023]Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://blog.liguanxin.cn/wp-content/uploads/2023/05/微信截图_20230529202716-150x53.png)
![论文笔记——[人脸3d重建][CVPR 2021 Oral]Inverting Generative Adversarial Renderer for Face Reconstruction](https://blog.liguanxin.cn/wp-content/uploads/2022/11/微信截图_20221107142415-150x83.png)
![论文笔记——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420151210-150x88.png)