
GFS(The Google File System)
GFS:用于大型分布式数据密集型应用程序的可扩展的分布式文件系统,提供容错能力,并为大量客户机提供了高聚合性能。
GFS和MapReduce区别:
GFS(2003年发表)使用商用硬件集群存储海量数据。文件系统将数据在节点之间冗余复制。
MapReduce(2004)是GFS架构的一个补充,因为它能够充分利用GFS集群中所有低价服务器提供的大量CPU。它与GFS一道形成了处理海量数据的核心力量,包括构建Google的搜索索引。不过这两个系统都缺乏实时随机存取数据的能力,意味着尚不足以处理Web服务。
简介
- 组件失效被认为是常态事件,因此持续的监控、错误侦测、灾难冗余以及自动恢复的机制必须集成在GFS中
- I/O操作和Block的尺寸都需要重新考虑
- 放弃覆盖的方式更新数据,而采用追加方式,数据的追加操作是性能优化和原子性保证的主要考量因素。(因此没有随机读写)
- 应用程序和文件系统API的协同设计提高了整个系统的灵活性。(对一致性要求没有那么高,追加操作原子性)
设计预期
- 主要两种读操作:大规模的流式读取和小规模的随机读取
- 写操作主要是许多大规模的、顺序的、数据追加方式的写操作。
系统架构
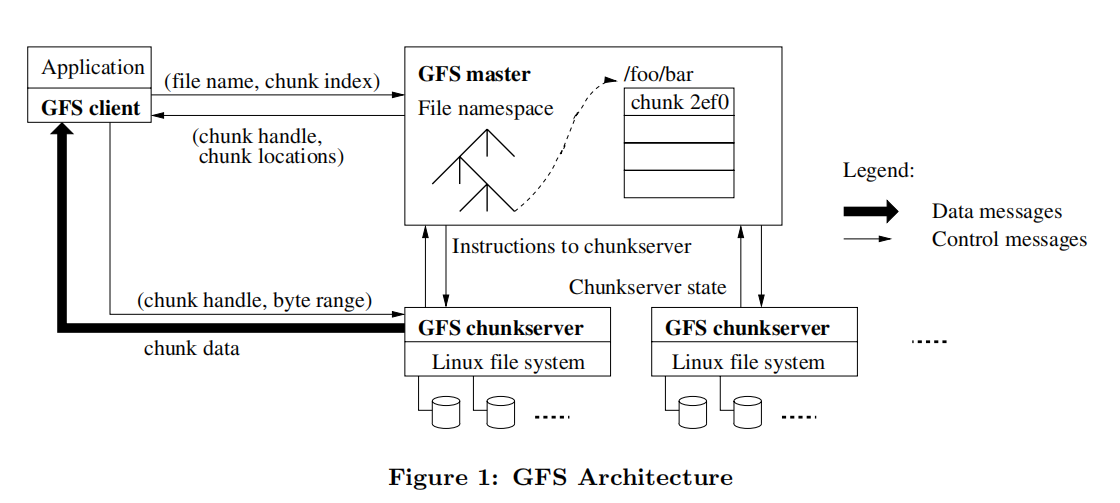
一个GFS集群包含一个单独的Master节点、多台Chunk服务器,并且同时被多个客户端访问。
GFS存储的文件都被分割成固定大小的Chunk。在Chunk创建的时候,Master服务器会给每个Chunk分配一个不变的、全球唯一的64位的Chunk标识。Chunk服务器把Chunk以linux文件的形式保存在本地硬盘上,并且根据指定的Chunk标识和字节范围来读写块数据。出于可靠性的考虑,每个块都会复制到多个块服务器上。缺省情况下,我们使用3个存储复制节点,不过用户可以为不同的文件命名空间设定不同的复制级别。
Master节点管理所有的文件系统元数据。这些元数据包括名字空间、访问控制信息、文件和Chunk的映射信息、以及当前Chunk的位置信息。Master节点还管理着系统范围内的活动,比如,Chunk租用管理、孤儿Chunk的回收、以及Chunk在Chunk服务器之间的迁移。Master节点使用心跳信息周期地和每个Chunk服务器通讯,发送指令到各个Chunk服务器并接收Chunk服务器的状态信息。
GFS客户端代码以库的形式被链接到客户程序里。客户端代码实现了GFS文件系统的API接口函数、应用程序与Master节点和Chunk服务器通讯、以及对数据进行读写操作。客户端和Master节点的通信只获取元数据,所有的数据操作都是由客户端直接和Chunk服务器进行交互的。
无论是客户端还是Chunk服务器都不需要缓存文件数据。客户端缓存数据几乎没有什么用处,因为大部分程序要么以流的方式读取一个巨大文件,要么工作集太大根本无法被缓存。无需考虑缓存相关的问题也简化了客户端和整个系统的设计和实现。(不过,客户端会缓存元数据。)Chunk服务器不需要缓存文件数据的原因是,Chunk以本地文件的方式保存,Linux操作系统的文件系统缓存会把经常访问的数据缓存在内存中。
元数据
Master服务器存储3种主要类型的元数据,包括:文件和Chunk的命名空间、文件和Chunk的对应关系、每个Chunk副本的存放地点。
前两种类型的元数据(命名空间、文件和Chunk的对应关系)同时也会以记录变更日志的方式记录在操作系统的系统日志文件中,日志文件存储在本地磁盘上,同时日志会被复制到其它的远程Master服务器上。采用保存变更日志的方式,我们能够简单可靠的更新Master服务器的状态,并且不用担心Master服务器崩溃导致数据不一致的风险。Master服务器不会持久保存Chunk位置信息。Master服务器在启动时,或者有新的Chunk服务器加入时,向各个Chunk服务器轮询它们所存储的Chunk的信息。
操作日志
操作日志包含了关键的元数据变更历史记录。是元数据唯一
的持久化存储记录,它也作为判断同步操作顺序的逻辑时间基线。
租约
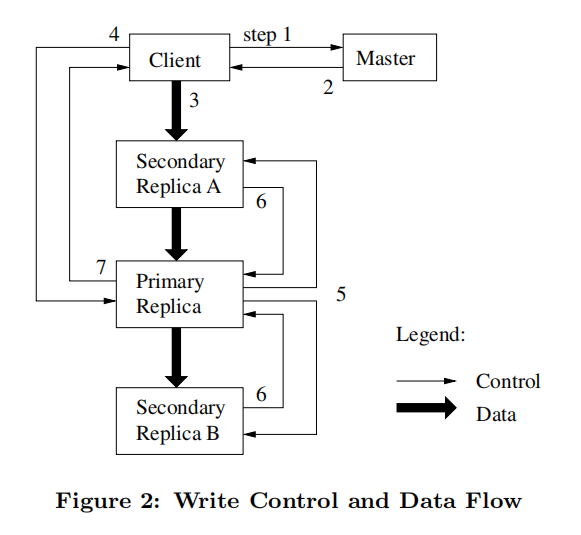
- 客户机向Master节点询问哪一个Chunk服务器持有当前的租约,以及其它副本的位置。如果没有一个Chunk持有租约,Master节点就选择其中一个副本建立一个租约(这个步骤在图上没有显示)。
- Master节点将主Chunk的标识符以及其它副本(又称为secondary副本、二级副本)的位置返回给客户机。客户机缓存这些数据以便后续的操作。只有在主Chunk不可用,或者主Chunk回复信息表明它已不再持有租约的时候,客户机才需要重新跟Master节点联系。
- 客户机把数据推送到所有的副本上。客户机可以以任意的顺序推送数据。Chunk服务器接收到数据并保存在它的内部LRU缓存中,一直到数据被使用或者过期交换出去。由于数据流的网络传输负载非常高,通过分离数据流和控制流,我们可以基于网络拓扑情况对数据流进行规划,提高系统性能,而不用去理会哪个Chunk服务器保存了主Chunk。
- 当所有的副本都确认接收到了数据,客户机发送写请求到主Chunk服务器。这个请求标识了早前推送到所有副本的数据。主Chunk为接收到的所有操作分配连续的序列号,这些操作可能来自不同的客户机,序列号保证了操作顺序执行。它顺序执行这些操作,并更新自己的状态。
- 主Chunk把写请求传递到所有的二级副本。每个二级副本依照主Chunk分配的序列号以相同的顺序执行这些操作。
- 所有的二级副本回复主Chunk,它们已经完成了操作。 主Chunk服务器回复客户机。任何副本产生的任何错误都会返回给客户机。在出现错误的情况下,写入操作可能在主Chunk和一些二级副本执行成
功。(如果操作在主Chunk上失败了,操作就不会被分配序列号,也不会被传递。)客户端的请求被确认为失败,被修改的region处于不一致的状态。我们的客户机代码通过重复执行失败的操作来处理这样的错误。在从头开始重复执行之前,客户机会先从步骤(3)到步骤(7)做几次尝试。
快照
当Master节点收到一个快照请求,它首先取消作快照的文件的所有Chunk的租约。租约取消或者过期之后,Master节点把这个操作以日志的方式记录到硬盘上。然后,Master节点通过复制源文件或者目录的元数据的方式,把这条日志记录的变化反映到保存在内存的状态中。新创建的快照文件和源文件指向完全相同的Chunk地址。
在快照操作之后,当客户机第一次想写入数据到Chunk C,它首先会发送一个请求到Master节点查询当前的租约持有者。Master节点注意到Chunke C的引用计数超过了1(Snapshot没有释放引用计数?)。Master节点不会马上回复客户机的请求,而是选择一个新的Chunk
句柄C’。之后,Master节点要求每个拥有Chunk C当前副本的Chunk服务器创建一个叫做C’的新Chunk。通过在源Chunk所在Chunk服务器上创建新的Chunk,我们确保数据在本地而不是通过网络复制。
垃圾回收
GFS在文件删除后不会立刻回收可用的物理空间。GFS空间回收采用惰性的策略。当一个文件被应用程序删除时,Master节点象对待其它修改操作一样,立刻把删除操作以日志的方式记录下来。但是,Master节点并不马上回收资源,而是把文件名改为一个包含删除时间戳的、隐藏的名字。当Master节点对文件系统命名空间做常规扫描的时候,它会删除所有三天前的隐藏文件。直到文件被真正删除,它们仍旧可以用新的特殊的名字读取,也可以通过把隐藏文件改名为
正常显示的文件名的方式“反删除”。当隐藏文件被从名称空间中删除,Master服务器内存中保存的这个文件的相关元数据才会被删除。这也有效的切断了文件和它包含的所有Chunk的连接。






