MapReduce是一种用于处理和生成大型数据集的编程模型和相关实现。
核心:
map函数:处理指定的键值以生成中间键值对。
reduce函数:合并关联的中间键对应的中间值。
概念类型:
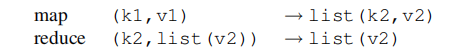
简单例子:
统计网站访问次数:map返回<URL, 1>,reduce发出<URL, total count>
MapReduce执行过程
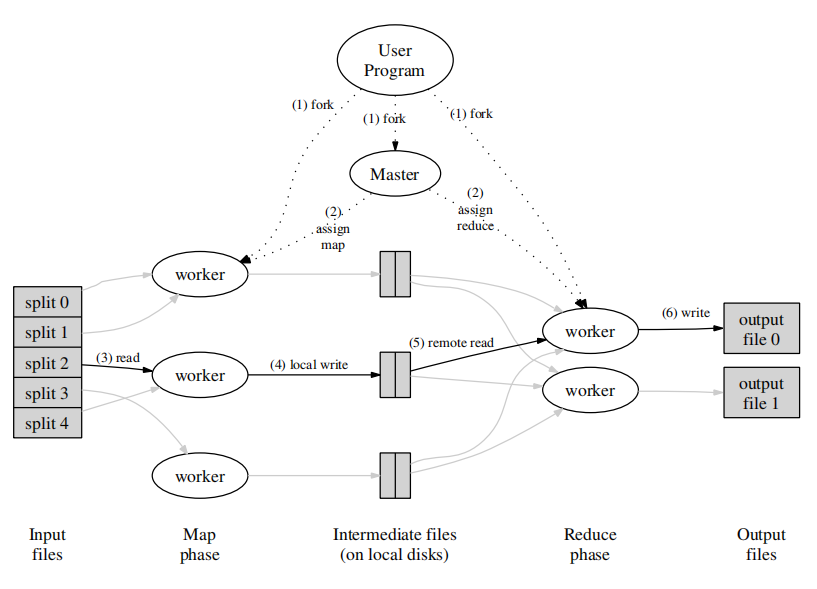
首先输入文件可以由不同的机器并行split为M份,用户可以指定一个分割函数和分割数量R来对中间键值对划分。
MapReduce函数开始后,会执行以下操作:
1、把输入文件split为16~64MB的M个文件。
2、剩余的worker将由master进程指派,master会挑选闲置的worker执行map或者reduce任务。
3、收到map任务的worker会处理相应的输入,将输入解析为键值对并调用用户定义的Map函数,产生的中间键值对会放入内存缓冲区。
4、缓冲区的键值对会周期性地写入本地,同时根据用户定义的分割函数分为R个部分。保存之后会把存放位置告诉master,master会转发给reduce worker。
5、当reduce worker被告知位置后,它会远程调用存储在map worker磁盘上的本地数据。读取完后会通过中间键对其进行排序,以便相同的键组合在一起。如果数据量太大,会使用外部排序。
6、reduce worker遍历排好序的中间数据,对于每个唯一的中间键,它会集合相应的中间值让用户定义的Reduce函数进行处理。Reduce函数的输出会追加到当前的输出文件中。
7、当所有map和reduce任务都完成,master会唤醒用户进程,把数据返回给用户。
通常完成后,用户不需要把R个输出文件合并成一个,这些文件会传递到另外的MapReduce处理。
Master数据结构
对每个map和reduce任务,存储其状态(空间,处理中,完成)
以及每个worker的状态(用于非空闲的任务)
master还会把中间文件的位置和大小转发给reduce worker。
MapReduce容错
-
worker失效
每隔一段时间master会ping每一个worker,如果某个worker一段时间内没有回应,则标记为不可用。如果worker失败,则对于它进行的map或reduce任务将重置为空闲,可以重新安排。
如果map任务对应的worker故障,则意味着对应的本地文件损坏,除了所有map worker要重新分配,也要通知reduce worker重新执行,且从新的存储路径获取。
而如果是reduce任务对应的某个worker故障,则已完成的reduce任务不需要重新执行,因为文件保存在全局文件系统中。
-
master失效
可以让master每隔一段时间保存一个checkpoint文件。如果master挂了,可以从checkpoint文件恢复。一般来说master失效的情况比较少见。
-
用户提供的map和reduce语义不明确
本地化
为了减少数据交换时的传输时间,通常会把输入数据先存储在离集群比较近的本地磁盘中。
备份任务
MapReduce执行时间较长通常是因为某个worker花费太时间。于是可以在当MapReduce接近完成的时候,将剩余的任务同时分给其他空闲的worker一起执行,当某个worker完成后标记为已完成。






