创新点:
①解决高分辨率图像的图像恢复任务中transformer复杂度高的问题
②在图像运动去模糊,去焦去模糊,图像去噪(高斯灰度/颜色去噪,和真实图像去噪)任务中取得sota
③self-attention中采用通道做乘法
④前馈网络的创新,采用门控网络
⑤网络早期用小patch大batch,逐渐到后期大patch小batch,很好地帮助网络从大图像中学习上下文,后期能提高性能
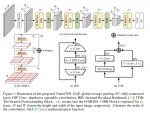
网络结构

- 总体采用UNet结构
多DW卷积头转置注意力(Multi-Dconv Head Transposed Attention)
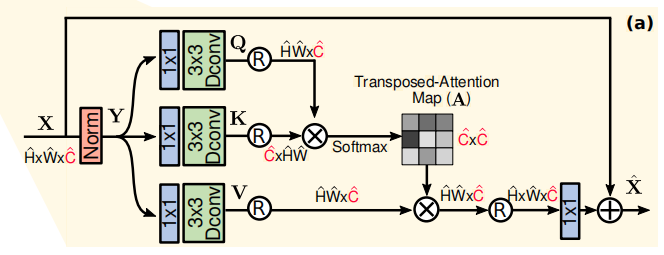
特点:通过只对通道做乘法,大大减少了计算量。
对于输入X首先经过layer norm,然后复制成三份作为QKV,经过11卷积增强通道上下文,然后经过33的DW卷积增强像素间的上下文,最后reshape成词向量的形式,QK相乘得到cc的子注意力矩阵,softmax后在与V相乘,再经过11卷积加上原本的X得到输出。
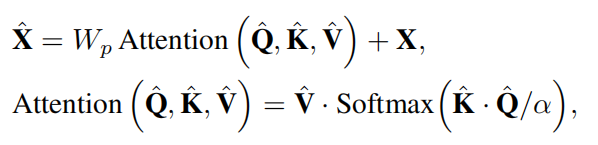
门控DW卷积前馈网络(Gated-Dconv Feed-Forward Network)
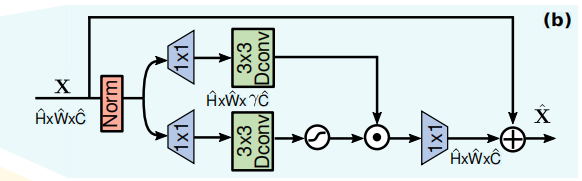
类似于原始的CA注意力,下方的通道被拓展到γ倍(通常是4倍),通过GELU非线性后与上方分支点乘。
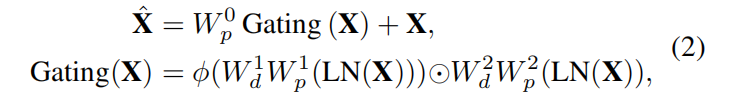
渐进式学习
基于CNN的网络通常会用固定patches的网络来训练。但是用小patches训练transformer网络的话,会导致无法有效编码全局信息,从而导致表现不是最优。
于是本网络在早期在较小的patches上训练,在后期在更大的patches上训练。
通过渐进学习在混合尺寸的patches上训练的模型在测试时显示出更好的表现。
由于在大patches上的训练的时间更长,我们随着patch size增加而减少batch size,以每个step的优化时间相同。
实验结果
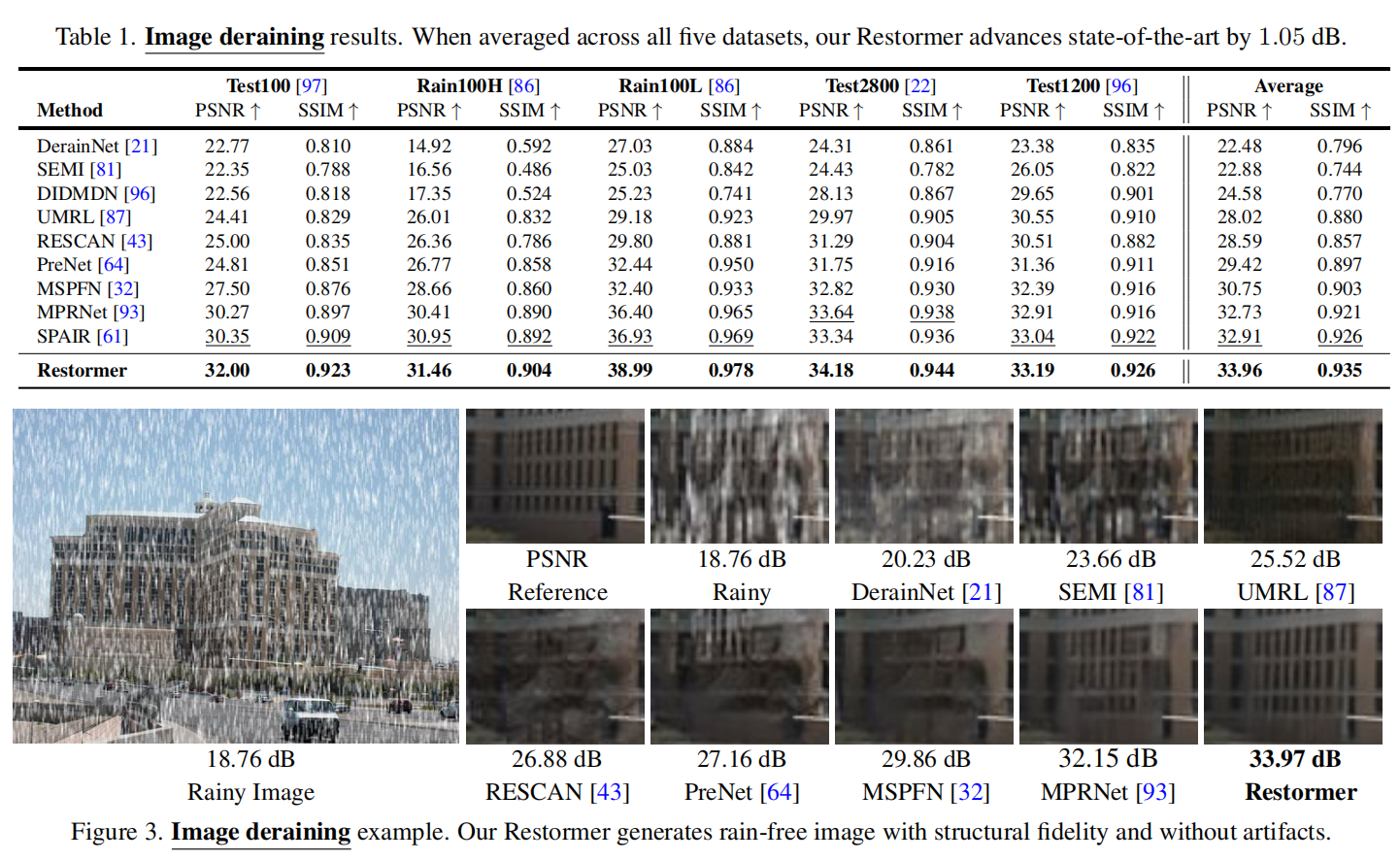
在去雨任务中psnr比其他网络平均高了1dB
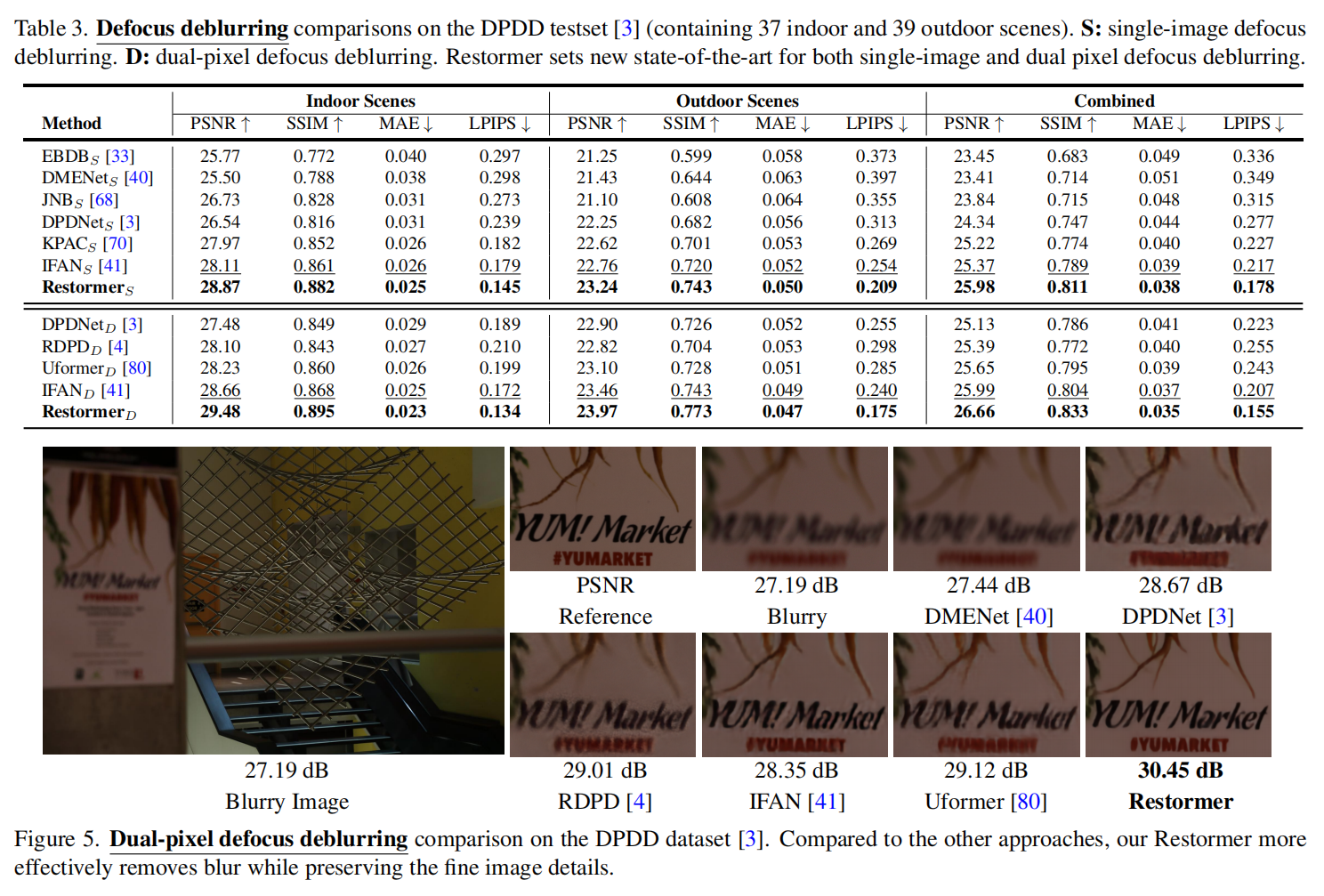
去模糊任务中也达到了sota
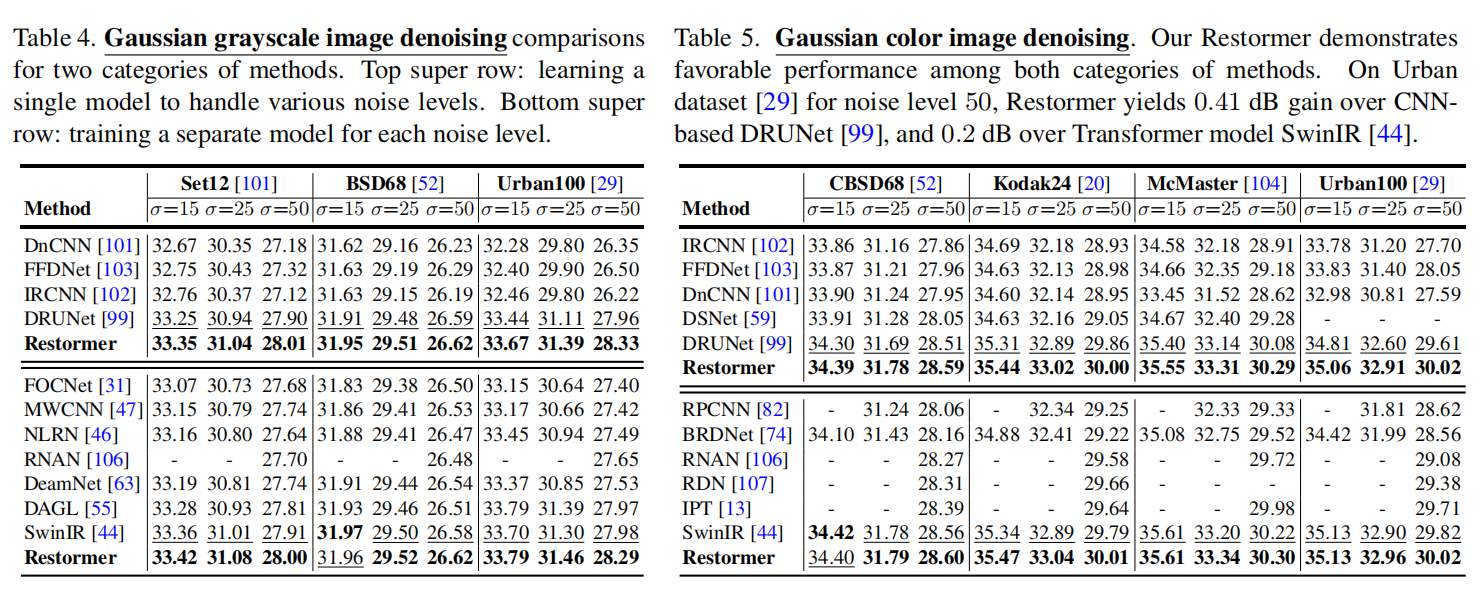
值得注意的是,在去噪任务中,本文方法基本上与SwinIR持平
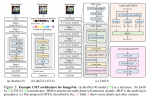
计算量
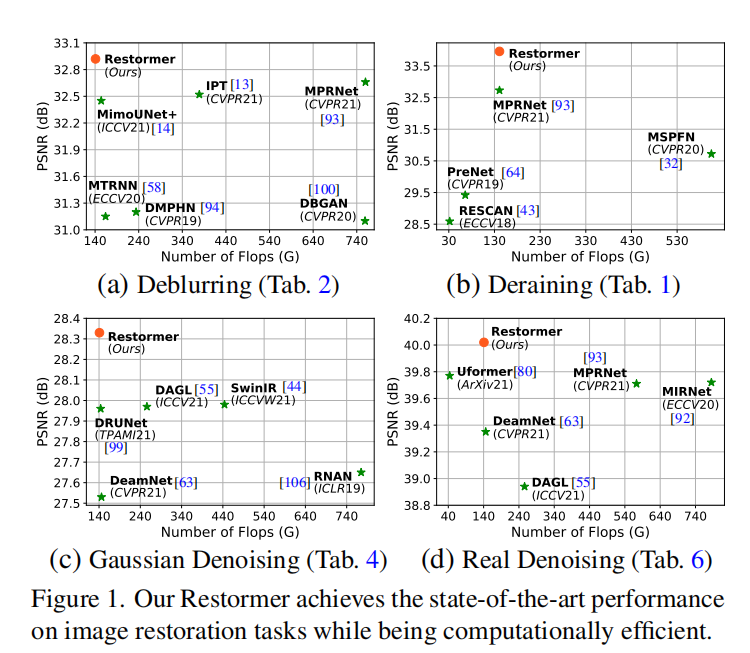
CODE
多DW卷积头转置注意力(Multi-Dconv Head Transposed Attention)
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b,c,h,w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
q,k,v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out = (attn @ v)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out门控DW卷积前馈网络(Gated-Dconv Feed-Forward Network)
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x![论文笔记——[CVPR 2022 Oral]MetaFormer is Actually What You Need for Vision](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220701190629-150x111.png)
![论文笔记——[CVPR2019]Noise2Void-Learning Denoising from Single Noisy Images](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420145844-150x89.png)
![论文笔记——[ICCV 2021 Oral]Co-Scale Conv-Attentional Image Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220713171240-138x150.png)