创新点:
①Transformer中的自注意力机制没用,结构才有用
②即便把Attention模块换成Pooling,也能得到提升

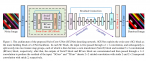
总体结构
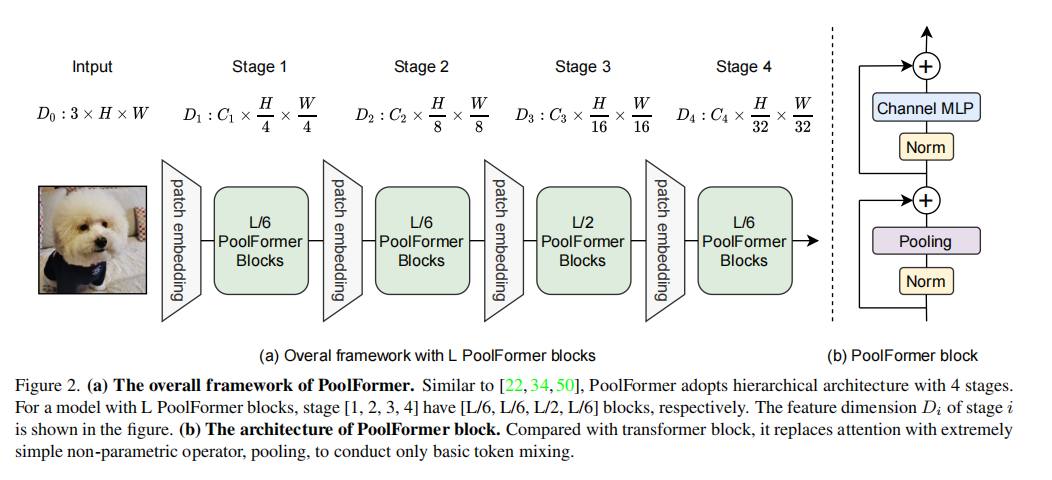
本文把Attention改成池化层
公式:
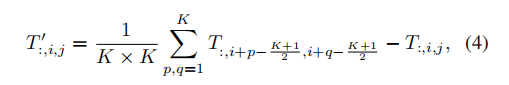
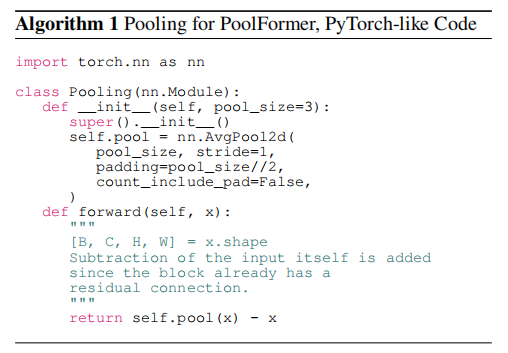
代码:
训练策略
数据增强: MixUp, CutMix, CutOut, RandAugment
训练轮数: 300epoch
优化器: AdamW
Weight Decay: 0.05
Peak Learning Rate: 1e^{-3}·batchsize/1024 (本文batch size为4096,学习率4e^{-3})
余弦策略减低学习率
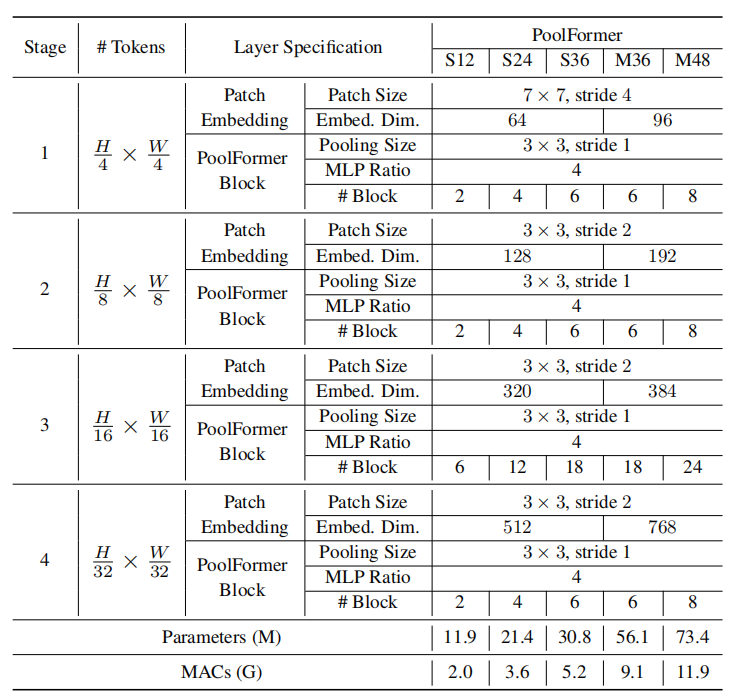
网络参数
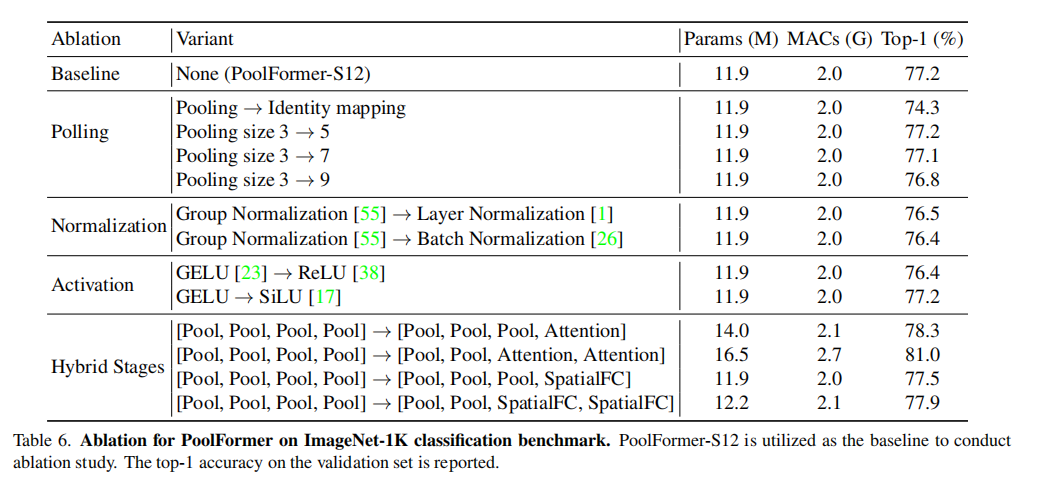
消融实验

![论文笔记——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420151210-150x88.png)
![论文笔记——[ICCV 2021]Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220725143207-150x86.png)