创新点:
①层次多头自注意力机制,减少计算/空间复杂度
②结合了transformer和CNN的优势
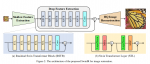
总体结构
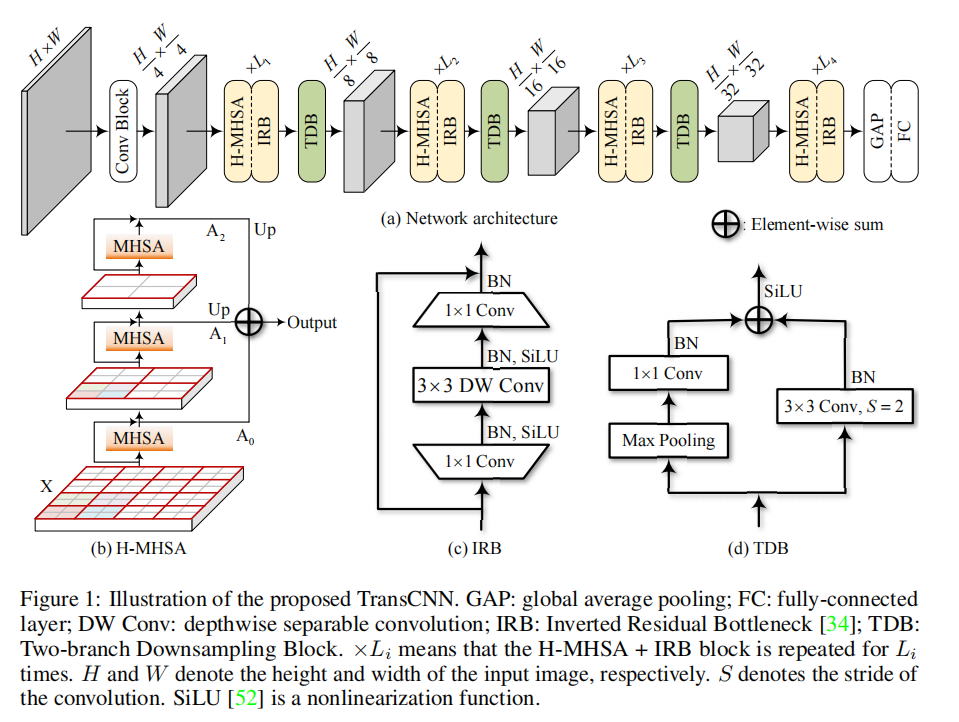
GAP:全局平均池化
FC:全连接层
DW Conv:深度可分离卷积
IRB:反向残差瓶颈层
TDB:双分支下采样模块
Li代表H-MHSA和IRB层重复Li次,S代表卷积步长,SiLU是非线性函数。
层次多头自注意力Hierarchical Multi-Head Self-Attention(H-MHSA)
相当于把H和W缩小G倍,可以理解为把一张图片拆分成多个G*G大小的图像块去计算自注意力。
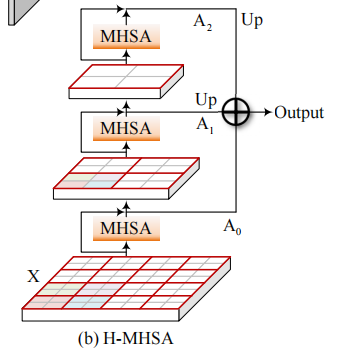
- 假设输入特征图X尺寸为H0*W0*C,则N=H0*W0,把特征图划分为G0*G0的小块,此时X’尺寸为(H0/G0*W0/G0)*(G0*G0)*C。
- 在这个尺寸下做自注意力,令Q=X'W^q,K=X'W^k和V=X'W^v,其中W^q,W^v,W^k的尺寸都是C*C
- 自注意力完了之后得到A0再把尺寸恢复为H0*W0*C,再加上残差使A0=X+A0
- 然后通过这个公式获得第二个初始图A0'=MaxPool_G1(A0)+AvePool(A0),然后重复前两步划分为G1*G1的小块,等。
- 最后得到多头自注意力的公式为(其中upsample为上采样)
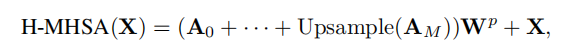
CODE
整体结构
class TransCNN(t.nn.Module):
def __init__(self,
num_classes,
in_channels = 3,
g_sizes = [[8, 4, 2], [7, 4, 2], [3, 2, 2], [2, 2, 2]],
exp_ratios = [4, 4, 6, 5],
repeats = [2, 2, 2, 2]):
super(TransCNN, self).__init__()
...
def forward(self, x):
# 1. 两套Conv2d、BatchNorm2d、ReLU三连
x_conv = self.conv(x)
x = x_conv
# 2. 基本TransCNNBlock模块,分为4个stage
for l in range(4):
transcnn_block = self.stages[l]
x = transcnn_block(x)
# 3. 全局平均池化
x_avg = self.avg(x)
x_avg = x_avg.squeeze()
# 7. 线性层和分类器
out = self.cls(x_avg)
return outTransCNNBlock模块
class TransCNNBlock(t.nn.Module):
"""Define TransCNN Block"""
def __init__(self, in_channels, embed_dim, g_size, exp_ratio, kernel_size = 3):
super(TransCNNBlock, self).__init__()
# 1. 层次多头自注意力机制
self.hmhsa = HMHSA(in_channels, g_size = g_size, out_channels = embed_dim)
# 2. 反向残差瓶颈层
self.irb = IRB(in_channels, exp_ratio = exp_ratio, kernel_size = kernel_size)
def forward(self, x):
x = self.hmhsa(x)
x = self.irb(x)
return x层次多头自注意力机制
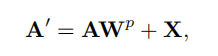
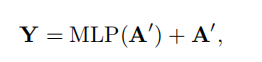
class HMHSA(t.nn.Module):
"""Define HMHSA module"""
def __init__(self, in_channels, out_channels, g_size = [8, 4, 2]):
...
def forward(self, x):
"""x has size [m, c, h, w]"""
# 1. step 0
x_0 = self.mg0(x) # 第一步,把图像划分成G0*G0大小的块
a_0 = self.mhsa0(x_0) # qkv乘法
a_0 = a_0.unsqueeze(dim = 3) # 恢复尺寸[m, h, w, 1, c]
a_0 = t.matmul(a_0, self.W_p0).squeeze().permute(0, -1, 1, 2) + x # 乘以权重矩阵,再做残差连接,如上图 # transformation # [m, c, h, w]
a_0_ = a_0
a_0 = a_0.permute(0, 2, 3, 1)
a_0 = self.mlp0(a_0) # 最后的mlp再做残差连接,如上图
a_0 = a_0.permute(0, -1, 1, 2) + a_0_ # 残差连接
x_0 = self.max_pool0(a_0) + self.avg_pool0(a_0)
# 2. step 1(重复以上步骤)
x_1 = self.mg1(x_0)
a_1 = self.mhsa1(x_1)
a_1 = a_1.unsqueeze(dim = 3) # [m, h, w, 1, c]
a_1 = t.matmul(a_1, self.W_p1).squeeze().permute(0, -1, 1, 2) + x_0 # transformation # [m, c, h, w]
a_1_ = a_1
a_1 = a_1.permute(0, 2, 3, 1)
a_1 = self.mlp1(a_1)
a_1 = a_1.permute(0, -1, 1, 2) + a_1_
x_1 = self.max_pool1(a_1) + self.avg_pool1(a_1)
# 3. step 2(重复以上步骤)
x_2 = self.mg2(x_1)
a_2 = self.mhsa2(x_2)
a_2 = a_2.unsqueeze(dim = 3) # [m, h, w, 1, c]
a_2 = t.matmul(a_2, self.W_p2).squeeze().permute(0, -1, 1, 2) + x_1 # transformation # [m, c, h, w]
a_2_ = a_2
a_2 = a_2.permute(0, 2, 3, 1)
a_2 = self.mlp0(a_2)
a_2 = a_2.permute(0, -1, 1, 2) + a_2_
# 4. Upsample(上采样再累加)
a_1 = self.upsample1(a_1)
a_2 = self.upsample2(a_2)
output = a_0 + a_1 + a_2
return outputIRB模块
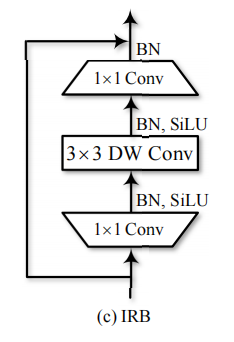
class IRB(t.nn.Module):
"""Define IRB module"""
def __init__(self, in_channels, exp_ratio, kernel_size = 3):
"""
Args :
--in_channel: input channels
--exp_ratio: expansion ratio
--kernel_size: default is 3
"""
super(IRB, self).__init__()
hid_channels = int(exp_ratio * in_channels)
self.layers = t.nn.Sequential(
t.nn.Conv2d(in_channels = in_channels, out_channels = hid_channels, kernel_size = 1),
t.nn.BatchNorm2d(hid_channels),
t.nn.SiLU(),
t.nn.Conv2d(in_channels = hid_channels, out_channels = hid_channels, kernel_size = kernel_size, padding = kernel_size // 2, groups = hid_channels),
t.nn.BatchNorm2d(hid_channels),
t.nn.SiLU(),
t.nn.Conv2d(in_channels = hid_channels, out_channels = in_channels, kernel_size = 1),
t.nn.BatchNorm2d(in_channels)
)
def forward(self, x):
x_ = self.layers(x)
return x + x_
![论文笔记——[CVPR2022]Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots](https://blog.liguanxin.cn/wp-content/uploads/2022/04/微信截图_20220420151210-150x88.png)
![论文笔记——[CVPR2022]A ConvNet for the 2020s](https://blog.liguanxin.cn/wp-content/uploads/2022/06/微信截图_20220630121941-150x101.png)
![论文笔记——[NeurIPS 2021]Focal Self-attention for Local-Global Interactions in Vision Transformers](https://blog.liguanxin.cn/wp-content/uploads/2022/07/微信截图_20220701221616-150x56.png)