Õłøµ¢░ńé╣’╝Ü
ŌæĀµ¢░ńÜäń╝¢ńĀüÕÖ©ń╗ōµ×ä’╝īµŖŖÕøŠÕāŵŖĢÕĮ▒Õł░W+ń®║ķŚ┤’╝łõĖÄõ╗źÕŠĆńÜäÕģłĶ┐śÕĤÕøŠÕāÅ’╝īÕåŹń╝¢ĶŠæõĖŹÕÉī’╝īµ£¼µ¢╣µ│ĢÕ£©W+ń®║ķŚ┤õĖŁń╝¢ĶŠæ’╝ēŃĆé
ŌæĪĶ»üµśÄõ║åÕøŠÕāÅńÜäWń®║ķŚ┤’╝īÕÅ»õ╗źµÅÉõŠøµÄ¦ÕłČÕÆīń╝¢ĶŠæńÜäĶāĮÕŖø
Ōæóķććńö©õ║åõĖĆõĖ¬ķóäÕģłĶ«Łń╗āÕźĮńÜäStyleGANµØźµüóÕżŹÕøŠÕāÅ
W+ń®║ķŚ┤
18õĖ¬õĖŹÕÉīńÜä512ń╗┤ÕÉæķćÅ’╝īµ»ÅõĖ¬StyleGANńÜäĶŠōÕģźÕ▒éõĖĆõĖ¬ŃĆé
ńĮæń╗£ń╗ōµ×ä

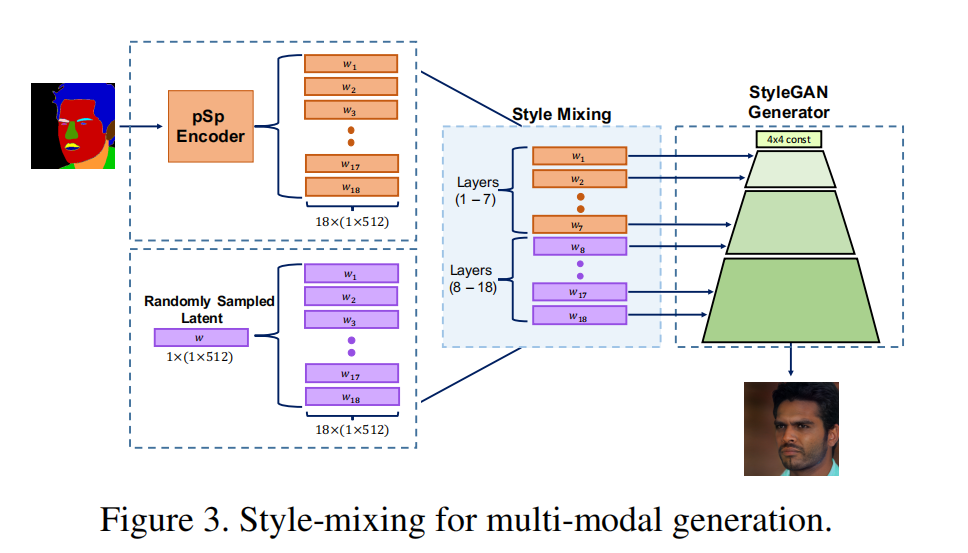
ÕøĀõĖ║ńĮæń╗£µś»µŖŖĶŠōÕģźµŖĢÕ░äÕł░18õĖ¬W+ń®║ķŚ┤’╝īÕøĀµŁżÕż®ńäČÕ£░µö»µīüÕżÜµ©ĪµĆüńÜäÕŁ”õ╣Ā’╝īÕ”éõĖŖÕøŠŃĆéõ║║ĶäĖĶĮ«Õ╗ōķĆÜĶ┐ćõĮÄń╗┤Õ║”’╝ł1-7Õ▒é’╝ēńÜäW+ń®║ķŚ┤Õ▒éĶŠōÕģź’╝īĶĆīķ½śń╗┤Õ║”’╝ł8-18Õ▒é’╝ēÕłÖµÄźÕÅŚµĀʵ£¼µĢ░µŹ«ńÜäķÜŵ£║ĶŠōÕģźŃĆé
ÕÅéĶĆāStyleGANńÜäStyle mixing’╝īµŖŖĶÄĘÕŠŚńÜä18õĖ¬ńē╣ÕŠüÕÉæķćÅõ╝ĀÕģźStyleGANńÜäõĖŹÕÉīÕ▒é’╝īõ╗ŻĶĪ©õ║åõ╗Äń▓Śń│ÖÕł░ń▓Šń╗åńÜäõĖŹÕÉīńē╣ÕŠüŃĆé
µĢłµ×£
ķÖżõ║åĶČģÕłå’╝īĶ┐ÖõĖ¬ńĮæń╗£Ķ┐śÕÅ»õ╗źµŗōÕ▒ĢÕł░ĶĮ«Õ╗ōńö¤µłÉõ║║ĶäĖ’╝īķü«µīĪńÜäõ║║ĶäĖĶ┐śÕĤ’╝īńöÜĶć│µś»ńī½ĶäĖńŗŚĶäĖŃĆé



CODE
õĖ╗ń╗ōµ×ä
def forward(self, x, resize=True, latent_mask=None, input_code=False, randomize_noise=True,
inject_latent=None, return_latents=False, alpha=None):
if input_code: # µś»ÕÉ”ĶŠōÕģźńÜ䵜»W+ń®║ķŚ┤ÕÉæķćÅ
codes = x
else:
codes = self.encoder(x) # Õ»╣ĶŠōÕģźÕøŠÕāÅĶ┐øĶĪīń╝¢ńĀü
# normalize with respect to the center of an average face
# ÕŖĀõĖŖÕØćÕĆ╝µØźÕĮÆõĖĆÕī¢
if self.opts.start_from_latent_avg:
if self.opts.learn_in_w:
codes = codes + self.latent_avg.repeat(codes.shape[0], 1)
else:
codes = codes + self.latent_avg.repeat(codes.shape[0], 1, 1)
# µś»ÕÉ”ÕŖĀÕģźķü«µīĪ
if latent_mask is not None:
for i in latent_mask:
if inject_latent is not None:
if alpha is not None:
codes[:, i] = alpha * inject_latent[:, i] + (1 - alpha) * codes[:, i]
else:
codes[:, i] = inject_latent[:, i]
else:
codes[:, i] = 0
input_is_latent = not input_code
# Ķ¦ŻńĀüÕÖ©’╝łõ╣¤µś»GANńÜäńö¤µłÉÕÖ©’╝ē
images, result_latent = self.decoder([codes],
input_is_latent=input_is_latent,
randomize_noise=randomize_noise,
return_latents=return_latents)
if resize:
images = self.face_pool(images)
if return_latents:
return images, result_latent
else:
return imagesń╝¢ńĀüÕÖ©ń╗ōµ×ä

def forward(self, x):
x = self.input_layer(x)
latents = []
modulelist = list(self.body._modules.values())
# ÕłåÕł½Õ»╣Õ║öń▓Śń│ÖŃĆüõĖŁńŁēŃĆüń▓Šń╗åńē╣ÕŠüńÜäµÅÉÕÅ¢
# ÕĘ”ĶŠ╣õĖēõĖ¬ĶōØĶē▓ÕØŚńÜäÕżäńÉå’╝īõĖĆńø┤ÕŹĘń¦»Õł░µĘ▒Õ▒é’╝īõ┐ØńĢÖõĖŁķŚ┤ńÜäõĖēõĖ¬ÕĆ╝Õüܵ«ŗÕĘ«
for i, l in enumerate(modulelist):
x = l(x)
if i == 6:
c1 = x
elif i == 20:
c2 = x
elif i == 23:
c3 = x
# c3õĖŁķŚ┤ÕĆ╝ÕłåÕł½Ķ┐øÕģźÕÉäĶć¬ńÜ䵫ŗÕĘ«ÕŹĘń¦»ÕØŚ’╝łµÅÉÕÅ¢õĖēń¦ŹõĖŹÕÉīńÜäÕ░Åńē╣ÕŠü’╝ē
for j in range(self.coarse_ind):
latents.append(self.styles[j](c3))
# Õ”éÕøŠńÜäskip connnect’╝īc3ÕŖĀÕŹĘń¦»ÕÉÄńÜäc2
p2 = self._upsample_add(c3, self.latlayer1(c2))
# p2õĖŁķŚ┤ÕĆ╝ÕłåÕł½Ķ┐øÕģźÕÉäĶć¬ńÜ䵫ŗÕĘ«ÕŹĘń¦»ÕØŚ’╝łµÅÉÕÅ¢Õøøń¦ŹõĖŹÕÉīńÜäõĖŁńŁēńē╣ÕŠü’╝ē
for j in range(self.coarse_ind, self.middle_ind):
latents.append(self.styles[j](p2))
# Õ”éÕøŠńÜäskip connnect’╝īp2ÕŖĀÕŹĘń¦»ÕÉÄńÜäc1
p1 = self._upsample_add(p2, self.latlayer2(c1))
# p1õĖŁķŚ┤ÕĆ╝ÕłåÕł½Ķ┐øÕģźÕÉäĶć¬ńÜ䵫ŗÕĘ«ÕŹĘń¦»ÕØŚ’╝łµÅÉÕÅ¢12ń¦ŹńÜäńÜäÕż¦ńē╣ÕŠü’╝ē
for j in range(self.middle_ind, self.style_count):
latents.append(self.styles[j](p1))
# µŖŖńē╣ÕŠüÕÉłÕ╣Č
out = torch.stack(latents, dim=1)
return outńö¤µłÉÕÖ©ń╗ōµ×ä(µØźĶć¬StyleGAN)
def forward(...):
# Õ”éµ×£ĶŠōÕģźõĖŹµś»ńē╣ÕŠüń®║ķŚ┤’╝īÕłÖÕåŹÕŖĀÕģźstylesõĖ¬fcÕ▒éĶ«®ĶŠōÕģźĶ┐øÕģźńē╣ÕŠüń®║ķŚ┤’╝łÕ»╣Õ║öStyleGANõ╗ÄzÕł░wń®║ķŚ┤’╝ē
if not input_is_latent:
styles = [self.style(s) for s in styles]
# µś»ÕÉ”ÕŖĀÕģźÕÖ¬ÕŻ░’╝łµÄ¦ÕłČĶŠōÕć║ńÜäõ║║ĶäĖń╗åĶŖé’╝īÕ”éÕż┤ÕÅæÕŹĘµø▓Õ║”’╝ē
if noise is None:
if randomize_noise:
noise = [None] * self.num_layers
else:
noise = [
getattr(self.noises, f'noise_{i}') for i in range(self.num_layers)
]
# µś»ÕÉ”ĶüܵŗóµĢ░µŹ«’╝ītruncationµś»Ķüܵŗóµ»öõŠŗ’╝ītruncation_latentµś»ÕØćÕĆ╝
if truncation < 1:
style_t = []
for style in styles:
style_t.append(
truncation_latent + truncation * (style - truncation_latent)
)
styles = style_t
if len(styles) < 2:
inject_index = self.n_latent
if styles[0].ndim < 3:
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
else:
latent = styles[0]
else:
if inject_index is None:
inject_index = random.randint(1, self.n_latent - 1)
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
latent = torch.cat([latent, latent2], 1)
# ÕÅéµĢ░Õī¢
out = self.input(latent)
# ń¼¼õĖĆõĖ¬SytleGANÕ▒é
out = self.conv1(out, latent[:, 0], noise=noise[0])
# Ķ┐śÕĤõĖ║RGB
skip = self.to_rgb1(out, latent[:, 1])
i = 1
# ÕÉÄń╗ŁńÜäSytleGANÕ▒é
for conv1, conv2, noise1, noise2, to_rgb in zip(
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
):
out = conv1(out, latent[:, i], noise=noise1)
out = conv2(out, latent[:, i + 1], noise=noise2)
skip = to_rgb(out, latent[:, i + 2], skip)
i += 2
image = skip
if return_latents:
return image, latent
elif return_features:
return image, out
else:
return image, None![Ķ«║µ¢ćń¼öĶ«░ŌĆöŌĆö[CVPR2022]A ConvNet for the 2020s](https://blog.liguanxin.cn/wp-content/uploads/2022/06/ÕŠ«õ┐Īµł¬ÕøŠ_20220630121941-150x101.png)
![Ķ«║µ¢ćń¼öĶ«░ŌĆöŌĆö[CVPR2019]Noise2Void-Learning Denoising from Single Noisy Images](https://blog.liguanxin.cn/wp-content/uploads/2022/04/ÕŠ«õ┐Īµł¬ÕøŠ_20220420145844-150x89.png)



![Ķ«║µ¢ćń¼öĶ«░ŌĆöŌĆö[CVPR 2022 Oral]MetaFormer is Actually What You Need for Vision](https://blog.liguanxin.cn/wp-content/uploads/2022/07/ÕŠ«õ┐Īµł¬ÕøŠ_20220701190629-150x111.png)

Ķ»äĶ«║ÕłŚĶĪ©