
Introduction
开源版本:
- Llama2 7B 13B 70B
- Llama 2-Chat 7B 13B 70B
训练过程:
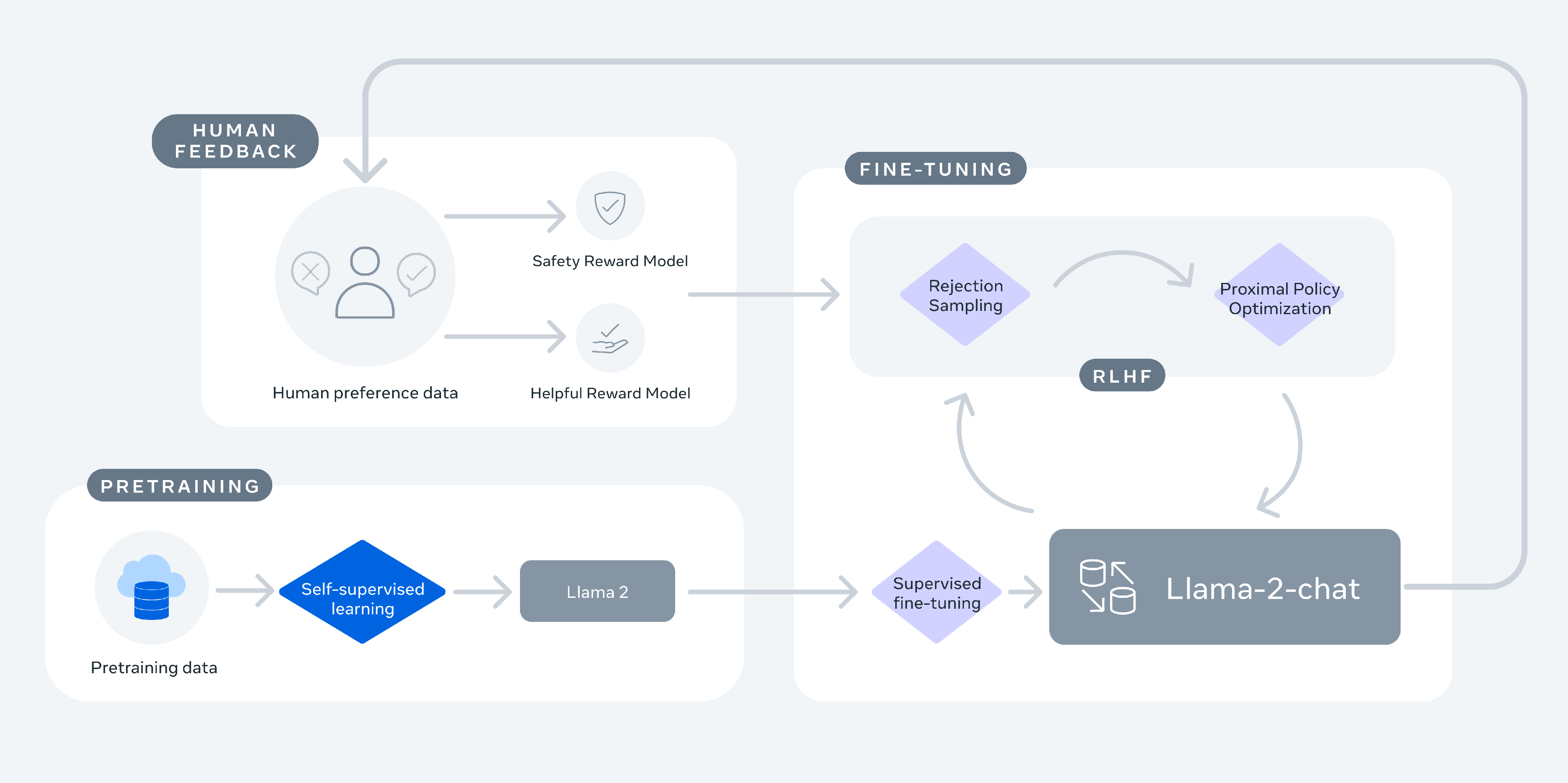
1、通过公开数据集训练Llama2。
2、通过有监督微调训练出Llama 2-Chat的初始版本。
3、使用人类反馈的强化学习(RLHF),如拒绝采样*和近端策略优化*(PPO)。
4、在整个RLHF阶段,与模型增强并行地积累迭代奖励建模数据对于确保奖励模型保持在分布范围内至关重要。
拒绝采样*:从一个容易采样的辅助分布中抽取样本,并使用某种接受/拒绝机制来决定是否保留所抽到的样本,从而确保最终得到的样本遵循目标分布。
近端策略优化*:核心思想是在策略更新时保持新旧策略之间的一个平衡点,即“近端”(proximal),这样可以防止新策略与旧策略相差太远而导致学习不稳定。PPO采用了一种称为剪裁(clipping)的技术来实现这一点,它限制了策略更新的方向和步长,使得新策略不会过于偏离旧策略。
Pretraining
-
预训练数据:2 trillion tokens
-
模型trick:
- RMSNorm
- SwiGLU
- RoPE
- GQA (grouped-query attention)
-
超参:AdamW、余弦衰减学习率(warmup=2000steps,final decay rate=10%)、weight decay*=0.1、gradient clipping=1.0
-
tokenizer: BPE (bytepair encoding),大小32k tokens
weight decay*:在损失函数中加入一个额外的项\lambda \sum_{i} w_i^2来惩罚权重向量的大小,从而防止模型过拟合。
预训练模型评估
- 代码:评估了我们的模型在HumanEval和MBPP上的平均pass@1得分;
- 常识推理:我们评估了PIQA、SIQA、HellaSwag、WinoGrande、ARC简单和挑战、OpenBookQA和CommonsenseQA的平均得分。对于CommonsenseQA,我们评估了7-shot结果,对于其他所有基准测试,我们评估了0-shot结果;
- World Knowledge:我们评估了 NaturalQuestions 和 TriviaQA 的 5-shot 性能;
- 阅读理解:我们评估了在SQuAD、QuAC 和 BoolQ 上的0-shot平均值;
- 数学:我们评估了GSM8K(8个样本)和MATH(4个样本)基准测试的平均结果
- Popular Aggregated Benchmarks:我们评估了MMLU(5个样本)、Big Bench Hard(3个样本)和AGI Eval(3-5个样本)的整体结果。对于AGI Eval,我们仅评估英语任务并报告平均结果。
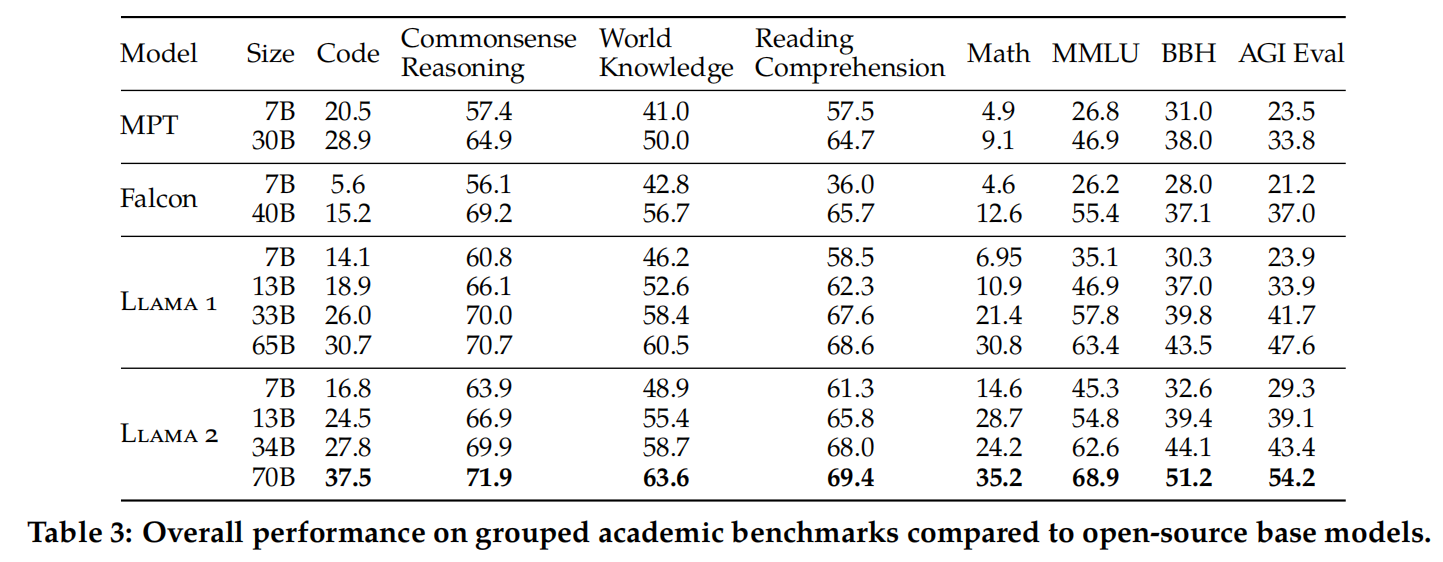
Llama 2模型相较于Llama 1模型有显著提升。具体而言,Llama 2 70B模型在MMLU和BBH基准测试中的得分分别比Llama 1 65B模型高出约5和8个百分点。除了代码基准测试外,Llama 2的7B和30B版本在其对应规模的所有类别上均超过了MPT模型的表现。
同时,在与Falcon的对比中,Llama 2的7B和34B版本在所有基准测试类别中也超越了Falcon 7B和40B模型。此外,Llama 2 70B模型的性能超越了所有已知的开源模型。为了进一步评估其性能,我们将Llama 2 70B模型与闭源模型进行了比较。
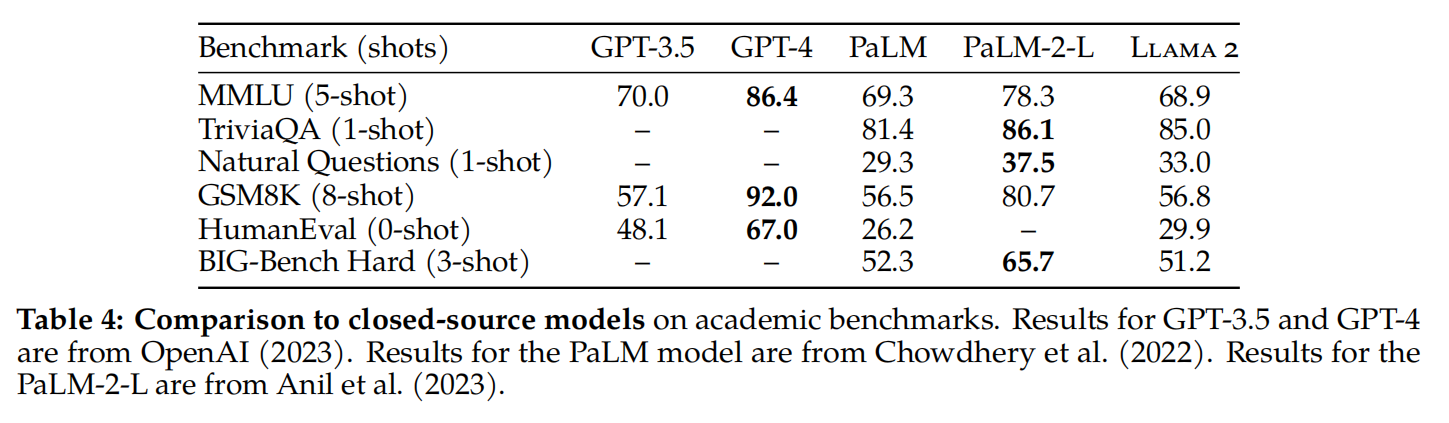
根据表4的数据,Llama 2 70B模型在MMLU和GSM8K基准测试中的成绩接近于GPT-3.5(由OpenAI在2023年发布),尽管在编码基准测试方面仍存在一定差距。值得注意的是,在几乎所有基准测试中,Llama 2 70B模型的表现要么优于PaLM(540B)模型(由Chowdhery等人在2022年提出),或者至少与其相当。不过,与GPT-4以及PaLM-2-L相比,Llama 2 70B模型仍然存在着较大的性能差距。
Fine-tuning
Llama 2-Chat是经过数月对齐技术研究和迭代应用的成果,其中包括指令调优和人类反馈强化学习(RLHF),这一过程需要大量的计算和标注资源。在本节中,我们将报告使用监督微调、初始及迭代奖励建模以及RLHF的实验和发现。此外,我们还将介绍一种新技术——Ghost Attention(GAtt),我们发现它有助于控制多轮对话的流程。
- SFT
Quality Is All You Need:数据可从多种渠道获取,但我们发现许多这类数据在多样性和质量上存在不足,尤其是在让语言模型适应对话式指令方面。为此,我们专注于收集高质量的SFT数据示例,如表5所示的数据集。通过从第三方数据集中筛选出数百万条示例,并结合我们自己供应商团队生成的少量但高质的注释,我们取得了显著的效果提升。这些结论与Zhou等人在2023年的研究相呼应,他们同样指出,有限规模的高质量指令调优数据便能产生优秀的模型性能。我们发现大约数万级别的SFT注释量就足以实现高质量的结果;在累积了总计27,540个注释之后,我们结束了这一阶段的工作。值得注意的是,在这个过程中我们没有使用任何元用户数据。
此外,我们注意到不同的注释平台和供应商可能导致模型性能上的显著差异,这强调了即便是在利用外部供应商的情况下,进行数据质量审核的重要性。为了确保数据的质量,我们详细审查了180个案例,并将人类注释的结果与模型通过人工审核生成的样本进行了对比。有趣的是,我们发现基于SFT模型生成的输出常常能够媲美甚至超越人工编写的SFT数据,这提示我们可以重新调整策略,将更多的注释工作重点放在RLHF(基于人类反馈的强化学习)的偏好注释上。
Fine-Tuning Details:微调过程采用余弦学习率,初始学习率为2×10-5。权重衰减为0.1,batch size is 64, a sequence length of 4096 tokens.
- RLHF
RLHF(Reinforcement Learning with Human Feedback,基于人类反馈的强化学习)是一种模型训练流程,它在预训练语言模型的基础上进一步实施微调,目的是使模型的行为更加符合人类的偏好并准确遵循给定的指令。在这个过程中,我们所收集的数据反映了抽样得出的人类偏好,具体做法是由人类注释员在模型给出的两个输出选项中挑选出他们认为更佳的一个。这些人类的选择反馈随后被用来训练一个奖励模型,该奖励模型能够学习并理解人类注释员的偏好规律,从而在未来不需要直接的人类干预下,也能依据所学的偏好模式自动做出决策。这种方法有效地将人类的主观判断转化为模型的优化方向,进而提升了模型生成内容的质量和相关性。
Human Preference Data Collection:接下来收集用于奖励建模的人类偏好数据。本模型选择了二元比较协议而不是其他方案,主要是因为它使我们能够最大化收集到的提示的多样性。
我们的标注程序如下:首先要求标注者写下一个提示,然后根据提供的标准在这两个模型样本响应之间作出选择。为了最大化多样性,对给定提示的两个响应是从两个不同的模型变体中采样的,并且通过改变temperature超参数来实现。除了让参与者进行强制选择外,我们还要求标注者标记他们对其所选响应的偏好程度:即他们的选择是显著更好、较好、略好还是几乎没差别/不确定。
在收集偏好标注时,我们关注的是有用性和安全性。有用性是指Llama 2-Chat的响应如何满足用户的请求并提供所需的信息;安全性是指Llama 2-Chat的响应是否安全,例如,“提供详细的炸弹制作说明”可能是有用的,但根据我们的安全指南这是不安全的。将二者分开可以使我们针对每一种情况应用特定的指导方针,更好地指导标注者;例如,我们的安全标注提供了集中于对抗性提示的指示等其他指导。
人类标注是按周分批收集的。随着我们收集了更多的偏好数据,我们的奖励模型得到了改进,我们也能够训练出渐进式更好的Llama 2-Chat版本。Llama 2-Chat的改进也改变了模型的数据分布。由于如果奖励模型没有接触到这种新的样本分布,其准确性会迅速下降,因此在新的Llama 2-Chat调优迭代之前收集使用最新Llama 2-Chat迭代的新偏好数据是很重要的。这一步骤有助于保持奖励模型与分布一致,并为最新模型保持准确的奖励。
本文收集了一个大型数据集,包含超过100万个基于人类应用他们指定的指南的二元比较,将其称为Meta奖励建模数据。与现有的开源数据集相比,本数据集的偏好数据具有更多的对话轮次,并且平均长度更长。
- 奖励建模
奖励模型接受模型生成的回复和相应的提示(包括之前对话的上下文)作为输入,并输出一个标量分数,以指示模型生成的质量(例如,有用性和安全性)。通过将这些回复分数作为奖励,我们可以在RLHF过程中优化Llama 2-Chat,以实现更好的人类偏好对齐和提高有用性和安全性。
有研究发现,有时在帮助性和安全性之间存在权衡,这使得单一奖励模型在两者上表现良好变得具有挑战性。为了解决这个问题,我们训练了两个独立的奖励模型,一个针对帮助性(称为Helpfulness RM),另一个针对安全性(Safety RM)。我们从预训练的聊天模型检查点初始化奖励模型,以确保两个模型都能从预训练中获得的知识的好处。简而言之,奖励模型“知道”聊天模型所知道的内容。模型架构和超参数与预训练语言模型相同,只是将下一个标记预测的 classification head 替换为用于输出标量奖励的 regression head。
