
ŚľļŚĆĖŚ≠¶šĻ†ÔľąReinforcement Learning, RLԾȜėĮšłÄÁßćśúļŚô®Ś≠¶šĻ†śĖĻś≥ēԾƝÄöŤŅášłéÁéĮŚĘÉÁöĄšļ§šļíśĚ•Ś≠¶šĻ†Ś¶āšĹēťáጏĖŤ°ĆŚä®ÔľĆšĽ•śúÄŚ§ßŚĆĖÁīĮÁßĮÁöĄŚ•ĖŚäĪ„ÄāšĽ•šłčśėĮŚĮĻŚľļŚĆĖŚ≠¶šĻ†ŚéüÁźÜ„ÄĀšĹúÁĒ®šĽ•ŚŹäŚ¶āšĹēśěĄŚĽļšłÄšł™ŚľļŚĆĖŚ≠¶šĻ†ś®°ŚěčÁöĄŤĮ¶ÁĽÜŤß£ťáäÔľö
ŚéüÁźÜ
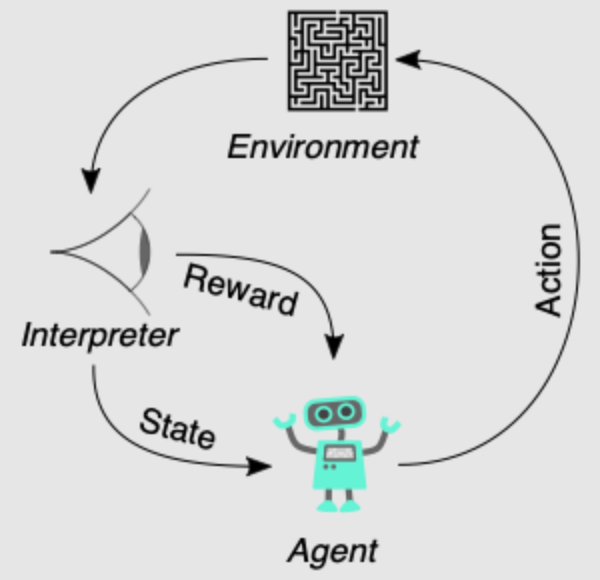
šĽ£ÁźÜÔľąAgentÔľČÔľöŚĀöŚáļŚÜ≥Á≠ĖÁöĄšłĽšĹď„Äā
ÁéĮŚĘÉÔľąEnvironmentÔľČÔľöšĽ£ÁźÜšłéšĻčšļ§šļíÁöĄŚ§ĖťÉ®Á≥ĽÁĽü„Äā
Áä∂śÄĀÔľąState, sÔľČÔľöÁéĮŚĘÉŚú®śüźšłÄśó∂ŚąĽÁöĄŚÖ∑šĹďśÉÖŚÜĶ„Äā
Śä®šĹúÔľąAction, aÔľČÔľöšĽ£ÁźÜŚú®śüźšłÄÁä∂śÄĀšłčŚŹĮšĽ•ťáጏĖÁöĄŤ°Ćšłļ„Äā
Ś•ĖŚäĪÔľąReward, rÔľČÔľöšĽ£ÁźÜťáጏĖśüźšłÄŚä®šĹúŚźéÁéĮŚĘÉŚŹćť¶ąÁöĄšŅ°ŚŹ∑ÔľĆÁĒ®šļ鍰°ťáŹŚä®šĹúÁöĄŚ•ĹŚĚŹ„Äā
Á≠ĖÁē•ÔľąPolicy, ŌÄÔľČÔľöšĽ£ÁźÜťÄȜ詌䮚ĹúÁöĄŤßĄŚąôśąĖŚáĹśēįԾƌŹĮšĽ•śėĮÁ°ģŚģöśÄßÁöĄśąĖťöŹśúļÁöĄ„Äā
ŚÄľŚáĹśēįÔľąValue Function, VÔľČÔľöŤĮĄšľįśüźšłÄÁä∂śÄĀÁöĄŚ•ĹŚĚŹÔľĆŤ°®Á§ļŚú®ŤĮ•Áä∂śÄĀšłčŤÉĹŤé∑ŚĺóÁöĄśúüśúõÁīĮÁßĮŚ•ĖŚäĪ„Äā
QŚáĹśēįÔľąQ-Value, QÔľČÔľöŤĮĄšľįŚú®śüźšłÄÁä∂śÄĀťáጏĖśüźšłÄŚä®šĹúÁöĄŚ•ĹŚĚŹÔľĆŤ°®Á§ļťáጏĖŤĮ•Śä®šĹúŚźéŤÉĹŤé∑ŚĺóÁöĄśúüśúõÁīĮÁßĮŚ•ĖŚäĪ„Äā
Q-learningÁģóś≥ē
import numpy as np
class GridWorld:
def __init__(self, size=5):
self.size = size
self.state = 0 # ŤĶ∑ÁāĻŚú®Ś∑¶šłäŤßí
self.end_state = size * size - 1 # ÁĽąÁāĻŚú®ŚŹ≥šłčŤßí
# Śä®šĹúÁ©ļťóīÔľöšłä(0)„ÄĀŚŹ≥(1)„ÄĀšłč(2)„ÄĀŚ∑¶(3)
self.action_space = [0, 1, 2, 3]
print(f"ŚąõŚĽļšļÜšłÄšł™ {size}x{size} ÁöĄÁĹĎś†ľšłĖÁēĆ")
print(f"ŤĶ∑ÁāĻšĹćÁĹģ: (0,0), ÁĽąÁāĻšĹćÁĹģ: ({size-1},{size-1})")
def get_state_coords(self, state):
"""ŚįÜÁä∂śÄĀśēįŚ≠óŤĹ¨śćĘšłļŚĚźś†á"""
return state // self.size, state % self.size
def reset(self):
self.state = 0
x, y = self.get_state_coords(self.state)
print(f"\nťáćÁĹģÁéĮŚĘÉԾƜôļŤÉĹšĹďšĹćÁĹģ: ({x},{y})")
return self.state
def step(self, action):
old_x, old_y = self.get_state_coords(self.state)
x, y = old_x, old_y
# ś†ĻśćģŚä®šĹúśõīśĖįšĹćÁĹģ
if action == 0: # šłä
x = max(0, x-1)
elif action == 1: # ŚŹ≥
y = min(self.size-1, y+1)
elif action == 2: # šłč
x = min(self.size-1, x+1)
elif action == 3: # Ś∑¶
y = max(0, y-1)
self.state = x * self.size + y
# ŚąįŤĺĺÁĽąÁāĻŚ•ĖŚäĪšłļ1ԾƌÖ∂šĽĖś≠•ť™§Ś•ĖŚäĪšłļ-0.1
reward = 1.0 if self.state == self.end_state else -0.1
done = self.state == self.end_state
action_names = ['šłä', 'ŚŹ≥', 'šłč', 'Ś∑¶']
print(f"Śä®šĹú: {action_names[action]}, šĽé({old_x},{old_y})Á߼Śä®Śąį({x},{y}), Ś•ĖŚäĪ: {reward:.1f}")
return self.state, reward, done
class QLearning:
def __init__(self, state_size, action_size, learning_rate=0.1, gamma=0.9):
self.q_table = np.zeros((state_size, action_size))
self.lr = learning_rate # Ś≠¶šĻ†Áéá
self.gamma = gamma # śäėśČ£Śõ†Ś≠ź
print(f"\nŚąĚŚßčŚĆĖQ-learningśôļŤÉĹšĹď:")
print(f"Ś≠¶šĻ†Áéá: {learning_rate}")
print(f"śäėśČ£Śõ†Ś≠ź: {gamma}")
print(f"QŤ°®Ś§ßŚįŹ: {state_size}x{action_size}")
def get_action(self, state, epsilon=0.1):
# epsilon-Ťī™Ś©™Á≠ĖÁē•
if np.random.random() < epsilon:
action = np.random.choice(len(self.q_table[state]))
print(f"śéĘÁīĘÔľöťöŹśúļťÄȜ詌䮚Ĺú {action}")
return action
action = np.argmax(self.q_table[state])
print(f"Śą©ÁĒ®ÔľöťÄČśč©śúÄšľėŚä®šĹú {action}")
return action
def learn(self, state, action, reward, next_state):
# 1. Ťé∑ŚŹĖŚĹďŚČćÁä∂śÄĀ-Śä®šĹúŚĮĻÁöĄQŚÄľ
old_value = self.q_table[state, action]
# 2. Ťé∑ŚŹĖšłčšłÄšł™Áä∂śÄĀšł≠śúÄŚ§ßÁöĄQŚÄľ
next_max = np.max(self.q_table[next_state])
# 3. Q-learningśõīśĖįŚÖ¨ŚľŹ
new_value = (1 - self.lr) * old_value + self.lr * (reward + self.gamma * next_max)
# 4. śõīśĖįQŤ°®
self.q_table[state, action] = new_value
def print_episode_summary(episode, total_reward, steps):
print(f"\nŚõ쌟ą {episode} śÄĽÁĽď:")
print(f"śÄĽś≠•śēį: {steps}")
print(f"śÄĽŚ•ĖŚäĪ: {total_reward:.2f}")
print("-" * 50)
# Ťģ≠ÁĽÉŤŅáÁ®č
env = GridWorld(size=5)
agent = QLearning(state_size=25, action_size=4)
episodes = 100 # šłļšļÜśľĒÁ§ļԾƜąĎšĽ¨ŚáŹŚįĎŚõ쌟ąśēį
for episode in range(episodes):
state = env.reset()
total_reward = 0
done = False
steps = 0
print(f"\nŚľÄŚßčŚõ쌟ą {episode + 1}")
while not done:
steps += 1
action = agent.get_action(state, epsilon=0.1)
next_state, reward, done = env.step(action)
agent.learn(state, action, reward, next_state)
state = next_state
total_reward += reward
if steps > 100: # ťė≤ś≠Ęśó†ťôźŚĺ™ÁéĮ
print("Śõ쌟ąś≠•śēįŤŅጧöԾƜŹźŚČćÁĽďśĚü")
break
print_episode_summary(episode + 1, total_reward, steps)
# śĮŹ10šł™Śõ쌟ąŚĪēÁ§ļšłÄś¨°QŤ°®
if (episode + 1) % 10 == 0:
print("\nQŤ°®ÁČáśģĶ:")
print(agent.q_table[:, :]) # ŚŹ™śėĺÁ§ļŚČć5šł™Áä∂śÄĀÁöĄQŚÄľ
šĽ£Á†ĀŤß£śěź
1.GridWorld ÁĪĽÔľö
- ŚąõŚĽļšłÄšł™ÁģÄŚćēÁöĄÁĹĎś†ľÁéĮŚĘÉ
- śôļŤÉĹšĹĮšĽ•šłäšłčŚ∑¶ŚŹ≥Á߼Śä®
- ŚąįŤĺĺÁĽąÁāĻŤé∑Śĺóś≠£Ś•ĖŚäĪԾƌÖ∂šĽĖś≠•ť™§Ťé∑ŚĺóŚįŹÁöĄŤīüŚ•ĖŚäĪ
QLearning ÁĪĽÔľö - ŚģěÁéį Q-learning Áģóś≥ē
- ÁĽīśä§šłÄšł™ Q Ť°®śĚ•Ś≠ėŚā®Áä∂śÄĀ-Śä®šĹúŚÄľ
- šĹŅÁĒ® őĶ-Ťī™Ś©™Á≠ĖÁē•ťÄȜ詌䮚Ĺú
- ťÄöŤŅáśó∂ŚļŹŚ∑ģŚąÜŚ≠¶šĻ†śõīśĖį Q ŚÄľ
Ťģ≠ÁĽÉŚĺ™ÁéĮÔľö - ŤŅźŤ°ĆŚ§öšł™Śõ쌟ąśĚ•Ťģ≠ÁĽÉśôļŤÉĹšĹď
- śĮŹšł™Śõ쌟ąťÉĹšĽéŤĶ∑ÁāĻŚľÄŚßčÔľĆÁõīŚąįŚąįŤĺĺÁĽąÁāĻ
ŤĺďŚáļÔľö
QŤ°®ÁČáśģĶ:
[[-0.29766024 -0.27952562 -0.24557464 -0.28062151]
[-0.2124381 -0.21151503 -0.1930229 -0.21528052]
[-0.15677518 -0.15030181 -0.10340539 -0.17394976]
[-0.10466175 -0.10065021 -0.09897863 -0.10862233]
[-0.07430568 -0.06793465 -0.05423492 -0.06129447]
[-0.22295002 -0.11124957 -0.21446148 -0.22789866]
[-0.19177152 0.06200571 -0.15535018 -0.19476545]
[-0.12503019 -0.10603329 0.25057189 -0.12785624]
[-0.08993588 -0.05934414 0.07503771 -0.06348727]
[-0.03940399 -0.03940399 0.22452878 -0.03948338]
[-0.17292671 -0.15084247 -0.15448072 -0.15648468]
[-0.12302759 0.02442123 -0.10888807 -0.12450674]
[-0.07707295 0.4344819 -0.05944325 -0.0677957 ]
[-0.03414978 0.61352714 0.01632828 -0.03240244]
[-0.01567082 0.05200123 0.79880578 0.03590251]
[-0.11063855 -0.1078826 -0.11357292 -0.11286845]
[-0.07876345 -0.06386965 -0.06959083 -0.07230351]
[-0.0306487 0.11765511 -0.034561 -0.0306487 ]
[-0.01 0.60844074 -0.01 -0.01171 ]
[ 0.09009701 0.25152601 0.99991536 0.10631137]
[-0.08317677 -0.08653641 -0.08582936 -0.08564389]
[-0.04145702 -0.01794207 -0.04900995 -0.05261765]
[-0.0199 0.21003608 -0.019171 -0.0109 ]
[-0.01673687 0.6861894 0.0071 0. ]
[ 0. 0. 0. 0. ]]