1. 核心改动总结
在此之前,DeepSeek v3.2 的 CP 实现(即 Native Sparse Attention 的 CP)存在一些局限性,比如只能支持 Batch Size = 1,且必须强制使用 DeepEP 后端,不支持 FP8 KV Cache。
主要改动:
- 新增 round-robin-split 模式:替代默认的 in-seq-split(按序列块切分)。新模式通过 token_idx % cp_size 的方式将 Token 均匀打散到各个 GPU 上。
- 解除限制:基于新的切分模式,解除了对 Batch Size 为 1 的限制,并允许使用 Fused MoE(单机性能通常优于 DeepEP)和 FP8 KV Cache。
2. 关键文件与代码改动详解
A. 参数与文档更新 (server_args.py, docs/…)
-
新参数 –nsa-prefill-cp-mode:
-
增加了 in-seq-split (旧默认值) 和 round-robin-split (新功能) 两个选项。
-
代码逻辑:在 server_args.py 中,如果用户开启了 NSA CP 且没有显式指定为 round-robin-split,代码会强制降级配置(MoE dense tp=1, backend=deepep, dtype=bf16, batch=1)。但如果选了 round-robin-split,这些强制限制就被移除了。
-
B. 核心切分逻辑 (python/sglang/srt/layers/attention/nsa/utils.py)
这是本次改动最底层的地方,定义了数据如何被切分。
-
nsa_cp_round_robin_split_data:
- 旧模式是将序列切成连续的块(Chunk)。
- 新模式(Round-Robin)的代码如下:
# 简化理解:按 GPU 数量进行取模分发 indices = torch.arange(cp_rank, tokens, cp_size, device=input_.device) return input_[indices]这意味着 Token 0 去 Rank 0,Token 1 去 Rank 1,Token 2 去 Rank 2… 以此类推。这种方式能更好地实现负载均衡。
-
Triton Kernel (nsa_cp_round_robin_split_q_seqs_kernel):
- 为了高效处理,引入了一个 Triton kernel 来计算打散后的序列长度和 Batch 索引。由于 Token 被打散,原本的序列长度在每个 GPU 上会变短,需要重新计算 cu_seqlens 等元数据。
C. 注意力层适配 (python/sglang/srt/layers/attention/nsa/nsa_indexer.py & nsa_backend.py)
- 支持打散后的 KV Cache:
- 修改了 get_indexer_kvcache_range 和 topk_transform 等方法,适配 round-robin 后的索引。
- 在计算 Attention 之前,数据已经被打散;计算完 Key/Value 后,通过 cp_all_gather_rerange_output 重新收集结果。
- 通信优化:
- 针对 round-robin 模式,专门优化了 gather 和 rerange(重排)的逻辑,确保打散计算后的结果能正确拼回原始序列顺序。
D. 调度策略优化 (python/sglang/srt/managers/schedule_policy.py)
-
解锁 Multi-batch:
-
旧代码:
if self.nsa_enable_prefill_cp and len(self.can_run_list) >= 1: return AddReqResult.OTHER # 强制只运行 1 个请求 -
新代码:
# 只有在旧模式(in-seq-split)下才限制 batch=1 if self.nsa_prefill_cp_in_seq_split and len(self.can_run_list) >= 1: return AddReqResult.OTHER -
这意味着如果使用 round-robin-split,调度器现在允许一次性为多个请求进行 Prefill,显著提升吞吐量。
-
E. 通信层 (python/sglang/srt/layers/communicator_nsa_cp.py)
- 重构了 NSACPCommunicateSimpleFn 等通信函数。
- 在 in-seq-split 和 round-robin-split 下,Scattered(分散)和 Full(完整)张量之间的转换逻辑不同。代码中增加了针对 nsa_enable_prefill_cp 的特定处理路径,允许在 Scatter 模式下直接进行 LayerNorm 和 Residual 累加,减少了不必要的通信开销。
F. 模型文件 (python/sglang/srt/models/deepseek_v2.py)
- 在模型的 Forward 过程中,将硬编码的检查替换为 nsa_use_prefill_cp(forward_batch) 工具函数调用。
- 这使得模型能够动态感知当前的 CP 模式,并在输入层、MoE 层和输出层正确地执行 cp_split_and_rebuild_data(切分数据)或 cp_all_gather_rerange_output(聚合数据)。
3. 如何开启?
在新版本中,启动 DeepSeek v3.2 服务时,推荐添加以下参数以获得最佳性能(特别是在单机多卡环境下):
python -m sglang.launch_server \
--model deepseek-ai/DeepSeek-V3.2-Exp \
--tp 8 --dp 1 \
--enable-dp-attention \
--enable-nsa-prefill-context-parallel \
--nsa-prefill-cp-mode round-robin-split \
--max-running-requests 324.一些细节
第一部分:旧版 CP 的实现与 Batch=1 限制
1. 旧版 CP (Sequence Splitting / in-seq-split) 是怎么做的?
旧版的 Context Parallelism(上下文并行)采用的是最直观的连续切分逻辑。
假设我们有一个长度为 8000 的 Prompt,我们在 8 张卡上运行(TP=8, CP=8)。
- Rank 0: 拿到 Token 0 ~ 999
- Rank 1: 拿到 Token 1000 ~ 1999
- …
- Rank 7: 拿到 Token 7000 ~ 7999
2. 为什么要限制 Batch Size = 1?
这种连续切分在多 Batch 场景下会遇到地狱级的负载均衡(Load Balancing)和索引对齐问题。
-
负载不均衡:
- 假设来了两个请求:Req A (8000 tokens), Req B (800 tokens)。
- Rank 0 需要处理 Req A 的 0~999 和 Req B 的 0~99。
- 但如果有一个请求特别短,且切分粒度很大,可能出现 Req C 只有 5 个 Token,导致只有 Rank 0 有活干,Rank 1-7 都在空转等待。
- 或者,Req A 的计算量远大于 Req B,导致流水线在等待最慢的那个 chunk 处理完。
-
索引管理的复杂性:
- DeepSeek V3 使用的是 NSA (Native Sparse Attention),需要复杂的 Block 索引。
- 如果 Batch > 1,且每个 Batch 的长度不同,每个 Rank 持有的 KV Cache 的物理位置和逻辑位置的映射关系会变得极其破碎。为了能正确计算 Attention,需要维护一套极其复杂的 Metadata 来说明“Rank 2 的第 X 个 Token 对应 Batch Y 的逻辑位置 Z”。
- 旧版妥协:为了工程实现的简单,旧代码索性强制要求 len(can_run_list) == 1,保证所有 GPU 只需要全心全意处理这一个大序列,索引是连续且可预测的。
第二部分:Fused MoE vs DeepEP
1. DeepEP (Deep Expert Parallelism) 是什么?
DeepEP 是 DeepSeek 官方为了解决跨节点的 All-to-All 通信效率而开发的库。
- 场景:主要为了解决大规模 MoE(专家并行)中,Token 需要被发送到不同 GPU 上的专家(Expert)去计算,计算完再发回来的场景。
- 机制:它是一套高度优化的通信+计算原语。在 DeepSeek V3 的原始设置中,为了极致性能,往往需要专门的通信内核来处理 Token 的分发。
- 旧版 CP 依赖 DeepEP:因为旧版是连续切分,Token 在 Rank 间的分布不一定符合专家的分布,或者为了配合 DeepSeek 原始代码的逻辑,强绑定了 DeepEP 后端。
2. Fused MoE 是什么?为什么它在这里更好?
Fused MoE(在 vLLM/SGLang 等推理框架中常见)是针对单机 TP(Tensor Parallel)环境高度优化的 Kernel。
- 机制:它不进行复杂的跨节点点对点 Token 传输,而是假设权重已经按 TP 切分好了。
- Fused(融合):它将“Gate(选专家) -> Sort(按专家重排 Token) -> GEMM(专家计算) -> Unsort(还原顺序)”这一系列操作,尽可能融合在 Kernel 内部或极少的 Kernel Launch 中完成。
- 优势:
- Round-Robin 的天作之合:新的 CP 模式(Round-Robin)将 Token 0,1,2,3… 均匀打散到 Rank 0,1,2,3…。这意味着每个 GPU 上都有一堆随机分布的 Token。这种分布天然适合数据并行类的处理,不再需要 DeepEP 那种复杂的调度。
- 开销更低:在单机场景下,SGLang 的 Fused MoE 实现比调用 DeepEP 的通信原语开销更小,且对 FP8 的支持更成熟(旧版 DeepEP 在 SGLang 接入中被锁定在 BF16)。
- 通用性:解除了对特定通信库的强依赖。
第三部分:KV Cache 的流动:打散、拼回与再打散
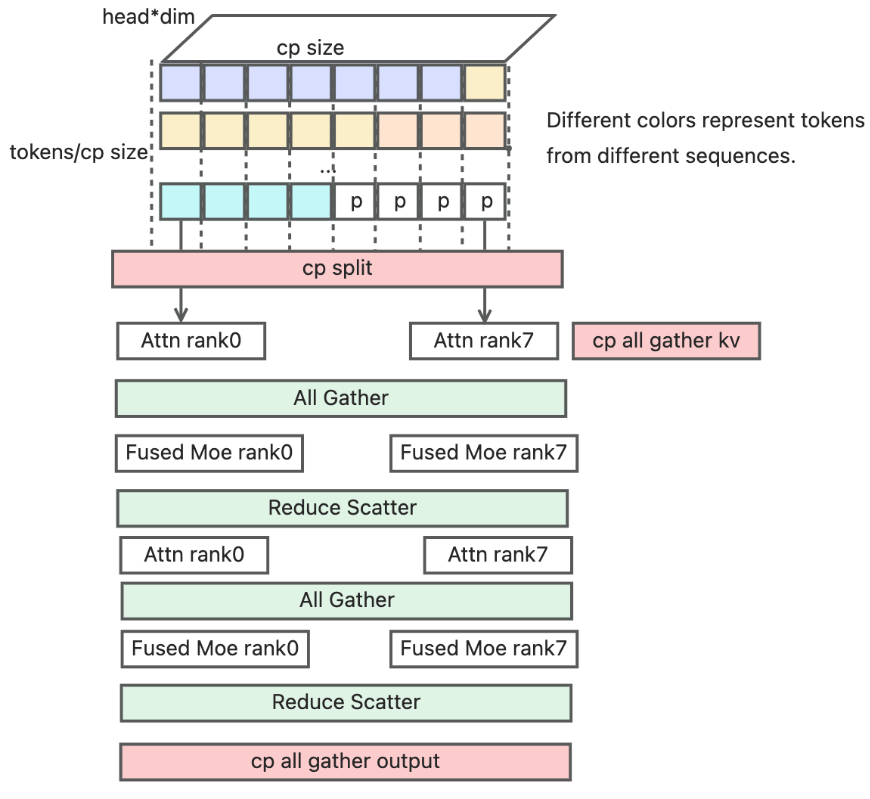
这是该 PR 最核心的改动:Round-Robin 模式下的数据流。
我们追踪一个 Batch 在 Prefill 阶段的生命周期。假设 CP=4(4张卡),一个序列 [T0, T1, T2, T3, T4, T5, T6, T7]。
1. 输入阶段:Round-Robin 打散 (Scatter)
在进入模型的第一层之前,输入 ID 被重新分发(代码中的 nsa_cp_round_robin_split_data)。
- Rank 0: 持有 [T0, T4]
- Rank 1: 持有 [T1, T5]
- Rank 2: 持有 [T2, T6]
- Rank 3: 持有 [T3, T7]
- 目的:绝对的负载均衡。无论 Batch 里有多少个请求,长短如何,每个 GPU 拿到的 Token 数量几乎完全一致(最多差 1 个)。
2. 前向计算:非 Attention 层 (MLP / Fused MoE)
在 MLP 或 MoE 层,计算是 Point-wise(逐 Token 独立)的。
- Rank 0 只需要计算 T0 和 T4 的投影。
- 如果是 MoE,Rank 0 就在本地算这两个 Token 的专家选择(Gate),然后根据 TP 策略(虽然这里叫 CP,但权重通常复用 TP 的切分)计算。
- 关键点:不需要通信,或者只需要常规的 TP All-Reduce。因为 Token 之间不需要互相“看见”。
3. 前向计算:Attention 层 (NSA) —— 最复杂的部分
Attention 必须要“看见”之前的 Token。比如 T5 (在 Rank 1) 需要 Attend to T0~T4 (分布在 Rank 0, 1, 2, 3)。
步骤 A: 计算 Q, K, V
- Rank 0 本地计算 T0, T4 的 Q, K, V 向量。
- 其他 Rank 同理。此时 KV Cache 还是打散存储的。
步骤 B: 聚合 KV (Gather & Rerange)
-
在计算 Attention score 之前,调用 cp_all_gather_rerange_output。
-
通信:所有卡进行 All-Gather。
- 瞬间,Rank 1 拿到了 Rank 0, 2, 3 的所有 K 和 V。
- 现在 Rank 1 拥有了完整的 global KV:{K0..K7}, {V0..V7}。
-
重排 (Rerange):由于 All-Gather 拿到的数据是按 Rank 拼接的(即 T0,T4, T1,T5…),内存是乱序的。需要根据 Round-Robin 规则,在内存中将其还原为逻辑顺序 T0, T1, T2…。
- 注:DeepSeek NSA 需要用到块索引,必须保证 KV 在逻辑上连续才能进行 top-k 筛选。
步骤 C: 计算 Attention
- Rank 1 使用本地的 Q (Q1, Q5) 去查询完整的 Global KV (K0~K7, V0~V7)。
- 计算出 Attention Output (O1, O5)。
步骤 D: 丢弃 Global KV (Implicit)
- 计算完后,Global KV 不需要保存(太大了)。
- Checkpointing 或 KV Cache Manager 只会保留 Rank 1 自己负责的那部分 KV (K1, K5) 落盘到显存 Cache 池中(用于后续 Decode)。
- 结果:Rank 1 现在手里有了 Context 后的结果 [O1, O5]。
4. 输出阶段
计算一直流转到最后一层。
- Rank 0 有 Logits[0], Logits[4]
- Rank 1 有 Logits[1], Logits[5]
- …
最终在采样(Sampling)之前,或者在最后一层,通常会再做一次 Gather 或者直接在分布式的 Logits 上做 Argmax(取决于采样策略),将结果拼回 [Token 0 ~ Token 7] 的顺序返回给用户。
